

人工知能の仕組みには数多くの種類があるため、手法の特徴や活用するモデルの選択が難しく感じるかもしれません。
本記事では、人工知能の分類についての全体像を理解するために、教師あり学習と教師なし学習に注目して、その特徴や相違点・共通点を解説します。学生の方や社会人の方はぜひ、代表的な2つの学習方法を理解してみましょう。

本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
機械学習とは
機械学習はデータの特徴や関係性を機械が自動的に獲得する仕組みです。従来はプログラマーが「〇〇なら猫」といった条件を事前に指定する必要がありましたが、機械学習を用いると判別に最適な条件を自動的に見つけることができます。
用語の違い
人工知能(AI, Artificial Intelligence)の明確な定義はなく、東京大学の松尾教授は「人工的につくられた人間のような知能、ないしはそれを作る技術」と定義しました。エンジニアによって条件付されたプログラムであっても人工知能に含むことがあります。
機械学習(ML, Machine Learning)は人工知能に含まれ、統計学に基づいた計算や脳の仕組みを模したニューラルネットなどのアルゴリズムを用いて、自動的に学習する分野を指します。
深層学習(DL, Deep Learning)は機械学習のニューラルネットの中でも層を深くしたモデル全般を指し、画像認識や自然言語処理、生成タスクにも広く活用されています。
種類
機械学習は大きく以下の4種類に分類されます。
- 教師あり学習
- 教師なし学習
- 半教師あり学習
- 強化学習
学習に利用するデータにラベルと呼ばれる正解値が有無や、学習の目的によって異なることを知っておきましょう。
人工知能にはデータの平均値や分散といった基礎的な統計指標を用いた条件分けプログラムから脳の仕組みを模した深層学習まで幅広く含まれるため、混合しないように注意しておきましょう。
教師あり学習
教師あり学習(supervised learning)は入力データと正解値のペアを用いて隠れた関係性や特徴を見つけ出すアルゴリズムです。代表的なタスクには分類と回帰があります。
代表的な分類タスクには、手描き画像のデータセットであるMNISTを用いた数字の認識AIが挙げられます。
代表的なアルゴリズム
教師あり学習は入力値と対応する正解値のペアデータを用いた機械学習手法です。数多くのアルゴリズムが考案されており、本記事では線形回帰と画像認識についてご紹介します。
線形回帰
線形回帰は連続的な数値を変数から予測するためのアルゴリズムです。体重から身長を予測する、最も単純な例を考えてみましょう。
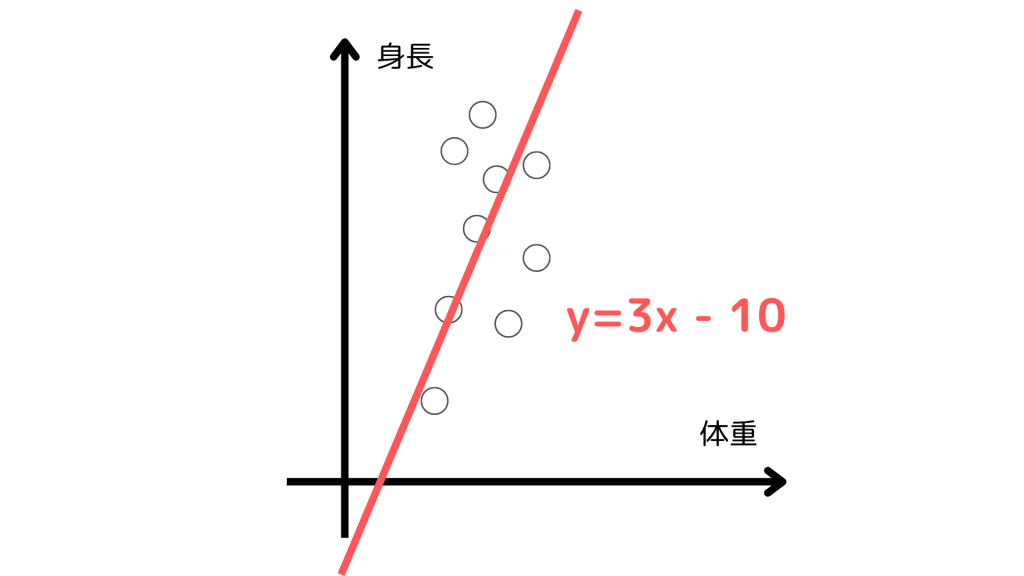
一般的に体重が増えると、身長も比例して高いというイメージがあります。この関係性を数学的に1次関数で近似することができ、関数近似に入力である体重と正解値である身長のペアを用いるため、教師あり学習の1つです。
複雑なデータに対しても、次数を高めることで柔軟に関数で近似できますが、過剰に適合する過学習と呼ばれる状態に陥らないように注意が必要です。
例えば、受験生が参考書を何周もして解答を覚えてしまい、テスト本番では十分な点数が得られない状態が過学習だと言えます。テストに対するスコアを高めるため、汎化性能を中心とした調整を行いましょう。
画像認識

画像の数字を検出するモデルを考えてみましょう。学習に用いるデータは画像と対応する数字の両方を含むペアです。横幅と縦幅が28サイズの画像では、28×28=784個の色の情報が集まったデータになります。
一般的に用いられる画像分類は、生物の脳を模したニューラルネットと誤差逆伝播法による学習です。機械が学習できるカギとなる誤差逆伝播は古くから活用され、機械学習の中心ともいえるアルゴリズムです。
機械学習ライブラリのPyTorchを利用して、手書き数字のデータセットであるMNISTを5つ表示するプログラムは以下のようになります。
import torch
import torchvision
from torchvision import transforms
import matplotlib.pyplot as plt
mnist_data = torchvision.datasets.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=True)
num_images = 5
data_loader = torch.utils.data.DataLoader(mnist_data, batch_size=num_images, shuffle=True)
data_iter = iter(data_loader)
images, labels = next(data_iter)
fig, axs = plt.subplots(1, num_images, figsize=(12, 4))
for i in range(num_images):
axs[i].imshow(images[i].squeeze(), cmap='gray')
axs[i].set_title(f"Label: {labels[i].item()}")
axs[i].axis('off')
plt.show()教師なし学習
教師なし学習(unsupervised learning)は、教師あり学習とは異なり、入力データに対する正解値やラベルが提供されない状況での機械学習アプローチです。
データ内の関係性や構造を発見し、データをクラスタリング、次元削減、異常検出、推薦システムの構築などのタスクに使用されます。
代表的なアルゴリズム
教師なし学習の仕組みは手法によって異なるため、代表的な2つのアルゴリズムを例に考えてみましょう。
k-means法
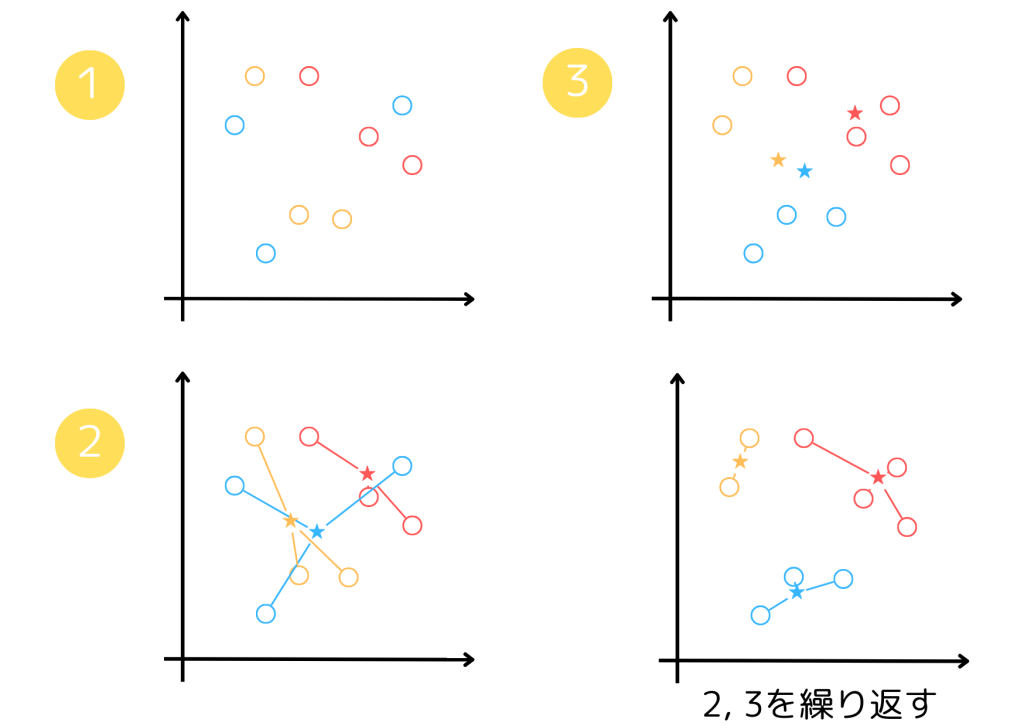
- データにランダムなクラスタを割り当てる
- クラスタの重心を計算する
- データのクラスタを重心からの距離が最も近いものに更新する
k平均法(k-means法)は1の後、2, 3の手順を繰り返し、データをグループ分けするシンプルなアルゴリズムです。処理を繰り返すごとに適切なデータのクラスタリングができ、例えば顧客の属性を調査するのに役立ちます。
Autoencoder
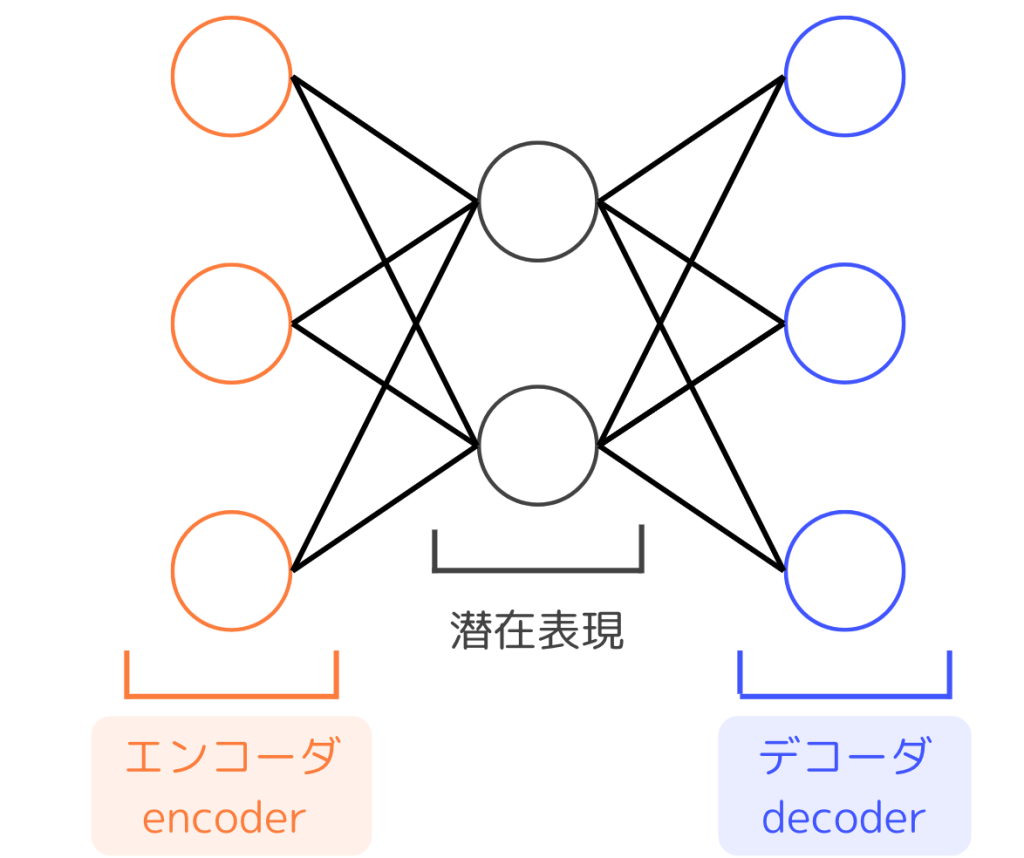
自己符号化器(Autoencoder)は図のようにニューラルネットワークを使用したモデルで、エンコーダとデコーダから構成されます。通常、中間層は入力層と出力層よりも次元数が小さく設定され、学習では出力を入力に近づけることが目的です。
数学的に言えば入力と同じものを返す恒等写像ですが、このモデルは重要な役割を持ちます。それは、潜在表現はデータの特徴をより小さい次元に圧縮した値であることです。
Autoencoderはデータの特徴をより小さい次元に圧縮する次元削減のアルゴリズムの1つで、人には理解しがたいデータにおいても効果を発揮します。全体的にモデルの処理を見ると、データを圧縮してからそれを元のデータに復元できるようなパラメータを学習します。
Autoencoderには
- Variational Autoencoder
- Denoising Autoencoder
- Sparse Autoencoder
など、学習方法を工夫した複数の派生モデルがあります。興味のある方はぜひ調べてみましょう。
半教師あり学習
教師あり学習や教師なし学習の特徴や違いについてご紹介しましたが、その中間である半教師あり学習(semi-supervised learning)と呼ばれる手法があります。
すべてのデータにラベルを付与するアノテーションは現実的に難しい場合があるため、一部のデータに対してラベル付けされる点が特徴的です。
生成モデルによるデータ拡張
文章・画像・動画などを自由に生成する生成モデル(Generative Model)を利用して新たにデータを生み出したり、ラベル付けされていないデータに対してアノテーションを自動的に行ったりできます。
人がアノテーションをしたデータに加えて、生成モデルでの新しいデータの拡張やラベル付与を利用して精度を高めてみましょう。
chatGPTに代表される生成AIは世界中で話題となり、ニュースや記事で頻繁に取り上げられます。かつては『AIに創造力はない』とされていたのに対し、文章や画像, 動画を自由に生成できるモデルの誕生はインパクトある出来事でした。
2014年GAN(Generative Adversarial Nets)がイアン・グッドフェロー氏から発表されました。GANは著名な人工知能の研究者に「機械学習においてこの10年間でもっとも面白いアイデアである」と称賛された画期的なアルゴリズムで、現在では派生したモデルが多く考案されています。
強化学習
強化学習(Reinforcement Learning)はエージェントと呼ばれる行動主体が環境との相互作用を通して、期待された行動の系列を学習するタスクを目的に利用される機械学習手法の1つです。
例えば、2016年にDeepMind社が開発したAlphaGoという強化学習モデルは囲碁のプロ棋士に勝利したと話題になりました。囲碁には10の360乗ほどの手があると考えられ、ボードゲームの中でも難しい分野です。
基礎知識
強化学習ではプレイヤーであるエージェントがある状態から行動によって得られる報酬を最大化することが目的です。数学的にはマルコフ決定過程(MDP)を用いて定式化され、報酬を最大化する最適な方策を発見するために試行錯誤を繰り返します。
次の時刻の状態は常に直前の状態と行動によって定まるマルコフ性を状態遷移が持つと仮定し、エージェントがある状態で生成する行動が従う分布である方策を条件付き分布として定めましょう。
報酬は一般的に割引率を考慮した割引報酬和で定義されますが、とある方策における報酬の期待値が期待報酬として扱われ、これが強化学習での目的関数です。割引率は即時的な報酬を重視する場合は小さく設定します。
強化学習を理解する上で、以下の関数が学習のカギとなります。
- 行動価値関数
- 状態価値関数
- アドバンテージ関数
行動価値関数とは状態と行動の組からある方策に従った場合における報酬の期待値です。状態価値関数は、状態からある方策に従った場合における報酬の期待値です。
行動価値関数とは少し異なり、行動価値関数から状態価値関数を引いたアドバンテージ関数はある状態での行動の相対的な良さを表す指標となります。
代表的なアルゴリズム
代表的なアルゴリズムとして、
- Greedy方策
- ε-greedy方策
の2つをご紹介します。
Greedy方策は決定論的方策で、行動価値関数が最も高い行動を常に選択するように学習が進みます。一方、ε-greedy方策は確率的方策で、εの確率でランダムな行動を選択する点が特徴的です。
現時点での最良な方策を常に選択すると、他にあったより良い行動が発見できない可能性があるため、探索的な行動と得られた方策の活用に関して、バランスを調整する必要があります。
例えるなら、学校のテスト範囲では問題集から出題されるという傾向を掴んだので「全ての解答を暗記する」方策と、「確率εで他の問題集や模擬試験も通して学習する」方策では、入試本番では後者の方がより良い成績が得られそうですね。強化学習では適切な探索が重要な学習プロセスに含まれます。
強化学習についてもっと知りたいという方は、下の記事をご覧ください。


『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
まとめ
教師あり学習/教師なし学習/半教師あり学習/強化学習について、それぞれの具体的なアルゴリズム例をご紹介しましたが、種類の多さに驚いたのではないでしょうか?
基本的な概念は共通する点が多いため、仕組みの中身に注目して比較することが、アルゴリズムを理解するのに役立ちます。ぜひ、ほかのモデルについても積極的に調べてみましょう。





