R言語はデータを扱うことにおいて強力なツールの一つであり、統計学的な解析からデータの可視化まで、幅広い用途で利用されています。本記事では以下のことを学んでいきましょう。
- R言語のインストールから基本構文
- データの読み込みと前処理
- 統計解析やデータ可視化の方法
また、実践的なデータ分析プロジェクトを通じて、学んだ知識をどのように応用するかも紹介します。
R言語でデータ分析のスキルを身につけ、データドリブンな意思決定を可能にしましょう。

本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
R言語とは何か?
R言語はデータ科学と統計分析の世界で広く用いられるプログラミング言語です。
その柔軟性と強力なデータ処理能力により、研究者、データアナリスト、そしてデータサイエンティストの間で重宝されています。
この章では、R言語の根底にある歴史とその独特な特徴について掘り下げていきます。
R言語の起源と発展
R言語は1990年代初頭、ニュージーランドのオークランド大学でロス・イハカとロバート・ジェントルマンによって開発されました。
当初は統計学の教育ツールとして考案されたものの、そのオープンソースの性質と拡張性の高さから、世界中の研究者やアナリストに急速に受け入れられました。
以来、R言語は絶えず進化を続け、統計解析、グラフィカルな表現、機械学習など、幅広いデータ分析の領域で使われるようになりました。
R言語の特徴と利点
R言語の最大の特徴は、統計分析とデータ可視化に特化している点にあります。
豊富なパッケージ群が提供されており、複雑なデータ分析が比較的簡単なコードで実行可能です。
また、オープンソースであるため、世界中の開発者によって常に新しい機能が追加されています。
Pythonなど他のプログラミング言語と比較した場合、R言語は統計学的手法の実装においてより直感的で、専門的な分析が求められる場面でその真価を発揮します。
PythonとR言語の違いについては以下の記事をご覧ください。

R言語のインストール方法
R言語を学び始める最初のステップは、適切なセットアップを行うことです。
この章では、Rとその強力なIDE(統合開発環境)、RStudioのインストールプロセスを簡潔に説明します。
RとRStudioの基本情報
Rはデータ分析と統計計算のためのプログラミング言語であり、RStudioはR言語のコードを書くための統合開発環境です。
RStudioはR言語の機能を拡張し、コードの記述、実行、デバッグを容易にする多数の便利な機能を提供します。
そのユーザーフレンドリーなインターフェースと強力なコーディングツールのため、R言語の学習と実践にRStudioが推奨される主な理由です。
インストール手順の詳細
RとRStudioをインストールするプロセスは直接的で簡単です。
- CRAN(The Comprehensive R Archive Network)からR言語の最新バージョンをダウンロードし、お使いのオペレーティングシステムに従ってインストールします。
- 次に、RStudioの公式ウェブサイトからRStudio Desktopの無料版をダウンロードし、同様にインストールします。
上記プロセスを完了すると、RStudioを開いてR言語のコーディングを開始できます。
初期設定では、作業ディレクトリの設定やパッケージのインストールなど、いくつかの基本的な設定を行うことが推奨されます。
R言語の基本構文
R言語の魅力の一つはその直感的で柔軟な構文にあります。この章では、R言語でのプログラミングの基礎となる変数の宣言やデータ型、関数の定義と使用方法について解説します。
変数とデータ型
R言語での変数宣言は、他の多くのプログラミング言語と同様に、データを格納するための容器として機能します。
R言語の主要なデータ型には、下記のようなものがあります。
数値(Numeric)
数値型は、整数や実数を含む数値データを扱う際に使用します。統計計算や数学的演算に頻繁に用いられ、例えば、データセット内の数値の平均値や合計を計算する際には数値型が必要です。数値型は、x <- 42やy <- 3.14のように宣言できます。
文字列(Character)
文字列型は、テキストデータを格納するために使用されます。例えば、データセット内の名前やカテゴリーのラベルなど、数値ではないデータを扱う際に文字列型が適しています。文字列は二重引用符(” “)または単引用符(’ ‘)で囲むことで宣言でき、name <- "John Doe"のように使用します。
論理値(Logical)
論理型は、真(TRUE)または偽(FALSE)の二つの値を取ります。条件文や論理演算において重要な役割を果たし、データのフィルタリングや条件に基づく処理を行う際に用いられます。例えば、is_valid <- TRUEのように宣言し、if文での条件判定などに使用します。
ベクトル(Vector)
ベクトルは、同じ型の要素を順序付けて格納する一次元配列です。数値、文字列、論理値のいずれか一種類のデータ型を持つことができ、データ分析において最も基本的なデータ構造の一つです。ベクトルはc()関数を用いて作成し、scores <- c(90, 85, 88)のように数値の集合を扱うことができます。
リスト(List)
リストは、異なる型のデータを格納できる複合データ構造です。ベクトル、リスト、データフレームなど、さまざまな型の要素を含むことができるため、複雑なデータ構造を扱う際に有用です。リストはlist()関数で作成し、data_list <- list(name="John", scores=c(90, 85, 88), passed=TRUE)のように異なる型のデータを一つにまとめることができます。
これらのデータ型を理解し、適切に使用することは、効率的なデータ分析の基礎を築く上で不可欠です。
関数の定義と使用
R言語には、データ分析を支援するための多様な組み込み関数が用意されています。例えば、sum()は数値の合計を計算し、mean()は平均値を求めるために使用されます。また、sd()関数は標準偏差を計算し、データのばらつきを評価するのに役立ちます。これらの関数は、データ分析の基本的な操作を簡単に行うことを可能にします。
ユーザーが独自の関数を作成することも、R言語の強力な機能の一つです。独自の関数を定義するには、functionキーワードを使用し、引数として処理したいデータを受け取り、そのデータに対して行いたい操作を記述します。以下に、簡単なユーザー定義関数の例を示します。
# 独自の関数を定義する例
myFunction <- function(x) {
result <- x^2 # 引数xの二乗を計算
return(result) # 計算結果を返す
}
# 定義した関数を使用する
myResult <- myFunction(4) # 4の二乗を計算
print(myResult) # 結果を表示この例では、単一の引数xを受け取り、その二乗を計算して返す簡単な関数myFunctionを定義しています。
このように、ユーザーは特定のタスクを効率化するために必要な処理を関数としてまとめ、何度も簡単に再利用することができます。関数を自分で作成することで、R言語でのデータ分析作業をより柔軟に、効率的に行うことが可能になります。
データの読み込みと前処理
データ分析プロジェクトの成功は、品質の高いデータに依存しています。この章では、R言語を使用して様々な形式のデータを効率的に読み込み、分析のためにデータをクリーニングして前処理する基本的な手法について解説します。
データのインポート
R言語では、read.csvやreadxlのような関数を使用して、CSVファイルやExcelファイルなど、様々な形式のデータを簡単に読み込むことができます。
これらの関数を利用することで、外部データソースからのデータを効率的にR環境にインポートし、分析の準備を行うことが可能になります。データのインポート方法を理解することは、データ分析プロジェクトの第一歩と言えるでしょう。
データクリーニングの基本
データクリーニングは、分析のためのデータを整理し、品質を向上させる過程です。
R言語では、na.omitやdplyrパッケージの関数を使用して欠損値を扱ったり、as.numericやas.factorなどの関数でデータ型を変換することができます。
これらの前処理手法を適用することで、データの一貫性を保ち、分析結果の信頼性を高めることができます。データクリーニングの基本を押さえることは、どのようなデータ分析プロジェクトにも不可欠なスキルです。
データ分析のための統計学基礎
統計学はデータ分析の心臓部であり、データから意味ある情報を引き出すために不可欠です。この章では、R言語を使って基本的な統計量を計算する方法と、データに対する統計的仮説検定を行う手順について学びます。
基本的な統計量の計算
データ分析において、平均、中央値、標準偏差はデータセットの中心傾向とばらつきを理解するための基本的な統計量です。
R言語では、mean()、median()、sd()といった関数を使用してこれらの統計量を簡単に計算できます。
これらの関数を適切に使用することで、データセットの概要を把握し、より深いデータ分析の基盤を築くことができます。
統計的仮説検定
統計的仮説検定は、データに基づいて特定の仮説が正しいかどうかを評価するための方法です。
R言語では、t.test()やaov()といった関数を使用して、t検定やANOVA(分散分析)などの基本的な仮説検定を実施できます。
これらの検定を通じて、データ間の関係性や差異が統計的に有意かどうかを判断し、データから有益な洞察を得ることが可能になります。

『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
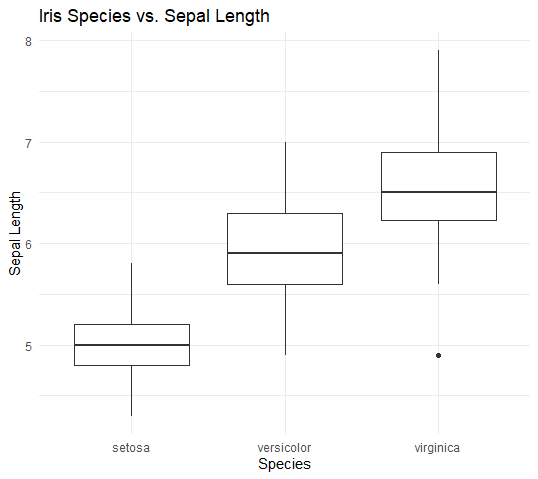
R言語によるデータ可視化
データの可視化は、複雑な情報を直感的に理解するための強力なツールです。R言語は、ggplot2などの強力なパッケージを通じて、美しく意味のあるグラフィックを作成する能力を提供します。
ggplot2によるグラフ作成
ggplot2は、R言語で最も人気のあるデータ可視化パッケージの一つで、その柔軟性とパワーにより広く利用されています。
このパッケージを使用することで、ユーザーは複雑なグラフィックも簡単に作成でき、データの洞察を視覚的に共有することが可能になります。
基本的なグラフタイプから始めて、カスタマイズオプションを追加する方法まで、ggplot2の使用方法を段階的に説明します。
効果的なデータの視覚化テクニック
データを視覚化する際には、ただグラフを作成するだけでなく、そのグラフが意味を伝えるようにすることが重要です。
- 色の使用
- レイアウトの選択
- 注釈の追加など
グラフをより効果的にするためのデザインテクニックを適用することで、データをより鮮明に伝え、視聴者に強い印象を与えることができます。