機械学習で出てくるCNN。機械学習を学習されている方の中には以下のような疑問を持たれている方はいませんか?
「よく聞くけど、どういったときに使用するの?」
「概要はわかったけど具体的に何をしているの?」
今回はそのような疑問をお持ちの方向けに、CNNの概要から実装までわかりやすく説明していきたいと思います。

本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
1.CNNとは何か
CNN、Convolutional Neural Networkはコンピュータが画像を理解するための仕組みで、画像の中のパターンや特徴を見つけることに長けています。普通のニューラルネットワークと違い、CNNは画像の一部を認識して、認識した部分を積み重ねて全体の特徴をつかみます。これによって、画像の中の物体や形を理解します。
これはもともと人間の視覚野をヒントに作られており、局所的な情報を重要視しつつ、位置の変化に強いモデルを作成可能であることが特徴です。CNNは画像認識だけでなく医療診断や自動運転などでも使われ、多くの分野で役立っています。
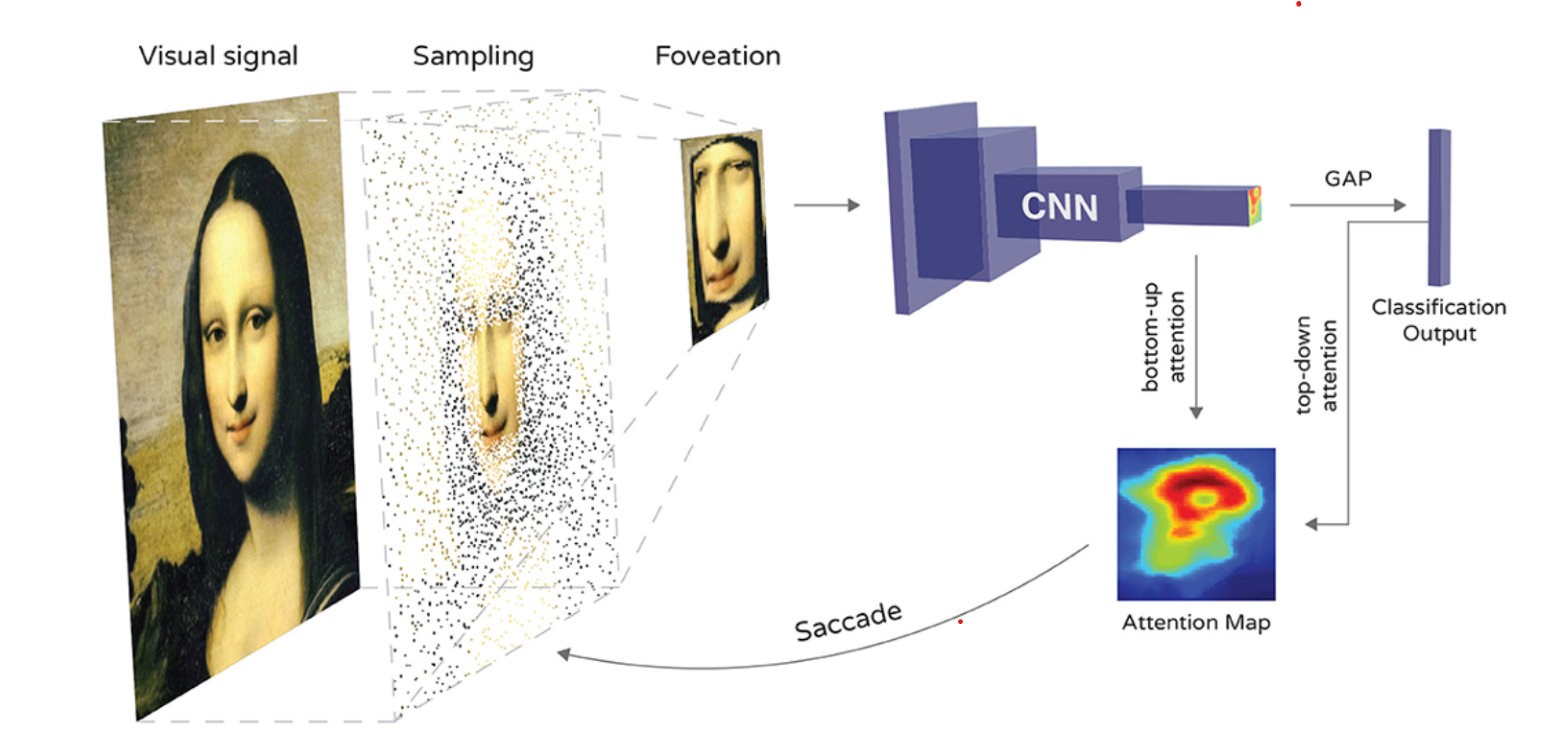
【参考:https://www.frontiersin.org/articles/10.3389/fncom.2021.746204/full】
2.畳み込み操作の流れと仕組み
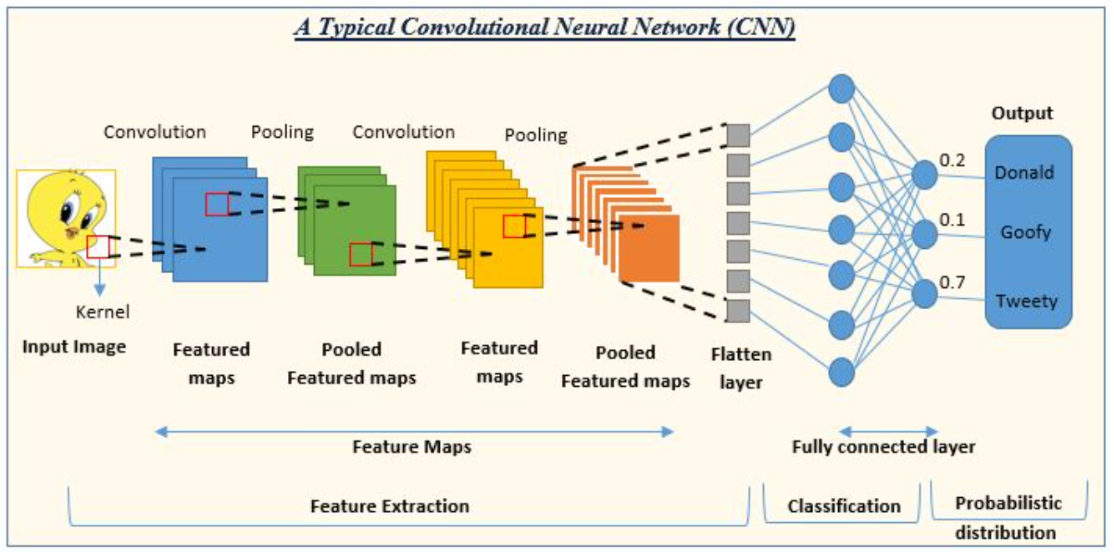
【参考:https://www.analyticsvidhya.com/blog/2022/01/convolutional-neural-network-an-overview/】
CNNは上図のように、まず図のFeature Mapsの部分でまず畳み込み層(Convolution Layer)、プーリング層(Pooling Layer)を繰り返し特徴を抽出していきます。その後、Flatten Layerで2次元の情報を1次元に変更し、最後に図の全結合層(Fully Connected Layer)が通常のニューラルネットワークと同じ働きをします。各層の働きを順に確認していきましょう。
3.畳み込み層、プーリング層、全結合層の役割と働き
①畳み込み層(Convolutional Layer)
畳み込み層は画像内の部分的な特徴を抽出するための層です。これは、カーネル、またはフィルタと呼ばれる小さな行列を使用して画像をスキャンし、各部位ごとに畳み込み演算を行います。計算方法は後ほど具体例を用いて確認します。
②プーリング層(Pooling Layer)
プーリング層は畳み込み層から得られた特徴マップを縮小する役割を果たします。プーリングによって特徴マップのサイズが削減されるため計算量が減少します。具体的にどのようなことを行っているかは後ほど具体例を用いて確認します。
③全結合層(Fully Connected Layer)
全結合層は畳み込み層とプーリング層から得られた特徴を元に最終的な分類や予測を行います。通常のニューラルネットワークと同じ構造で最終的なクラス分類が行われます。
4.畳み込みカーネルの役割と畳み込み演算の計算方法
①畳み込みの計算方法
畳み込み層の最初のステップは、入力画像に対してカーネルを適用することです。カーネルは、下図紫色のブロックに示すように小さな行列であり、これを学習することによりモデルの精度を上げていきます。今回は説明のためにこのサイズを用いていますが、通常はInputに対して十分に小さいサイズを適用します。カーネルは特定の特徴を強調するように設計されており、画像上をスライドしながら順に畳み込み演算を行います。
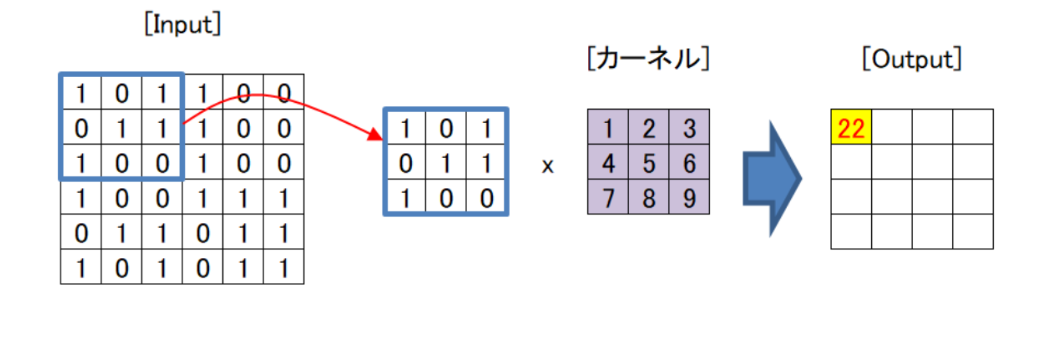
上に示すように、縦×横が6×6のInputに3×3のカーネルを適用することを考えます。まずはInputの青枠部分を抜き出し、カーネルの同じ部分をかけ合わせてすべて足します。図の場合、左上から順に
「1×1+0×2+1×3+0×4+1×5+1×6+1×7+0×8+0×9=22」
となり、Outputの一番左上の数値は22になります。
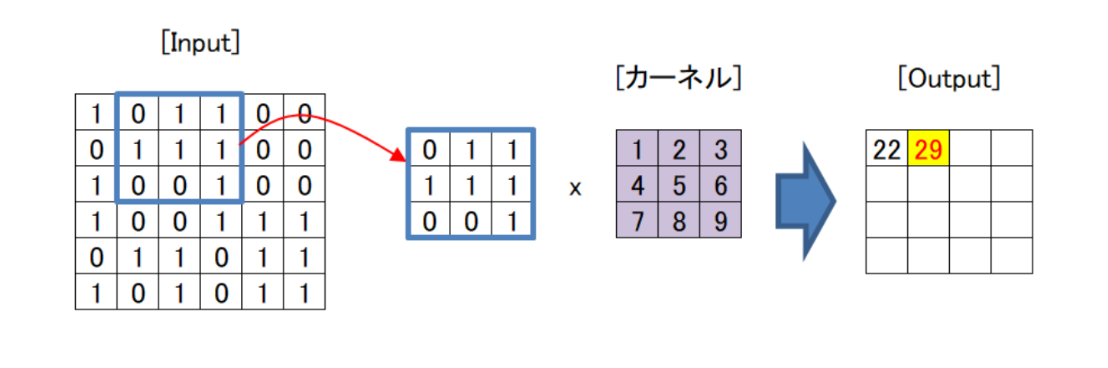
次にInputの青枠を右側に一つ移動し、同じことを繰り返します。この場合、
「0×1+1×2+1×3+1×4+1×5+1×6+0×7+0×8+1×9=29」
となります。これを繰り返すことにより、上図のように6×6のInputに3×3のカーネルを適用すると4×4のOutputが得られます。このようにして図のOutput部にあたる特徴マップを生成します。
②ストライド
Input青枠部分の一つ目を計算し、その次に青枠を右側に移動する距離をストライドといいます。先ほどはわかりやすくするため、1つ目の計算が終わった後、青枠を一つ右側に移動しました。この場合のストライドは1です。この量をパラメーターで設定可能です。
ストライドの量を増やすとOutputのデータ量を削減可能です。例えば上図の場合、ストライドを1から3に変更するとOutputは2×2になりOutputのデータが削減されます。ただし、図のイメージからわかるようにストライドを増やしてデータを削減すると計算量が減ることからもわかるようにOutputに反映される情報が減少するため、特徴をモデルにうまく反映できる範囲で調整が必要です。
また、この例でストライドを2に設定した場合のように、計算ができない場合もありますので注意が必要です。(できる範囲で勝手に計算してくれるものもあるそうですが、理解したうえで使用したいですね。)
③パディング
上の図を見るとわかるように、この規則で計算をしていくとInputの外周部分はほかの部分に比べて計算を行う回数が少なく、ほかの部位に比べて情報の反映が少なくなってしまう場合があります。
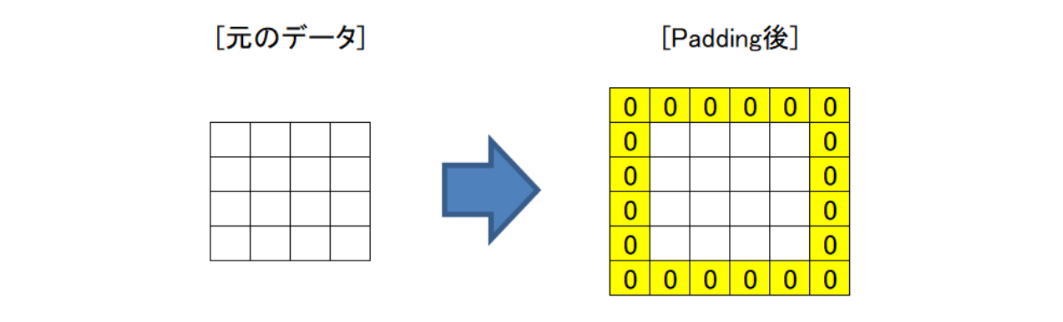
そこで図のように、外周を「0」で埋めてやることにより外周周辺の情報もモデルに反映してあげることが可能です。このような処理をパディングと言います。
5.プーリング層の役割と種類(最大プーリング、平均プーリング)
プーリングは一定の手順でデータの重要な情報のみ抜き出し、特徴を保持したままデータ量を削減します。また、特徴のみ抜き出すことにより該当エリアのノイズに左右されないモデルを作ることができます。これにより対象としているものの位置が変わったり、関係ないものが入っていても精度が下がらないモデルを作成可能です。プーリングには大きく分けて「最大プーリング」と「平均プーリング」の2種類が存在します。
最大プーリングは領域内で最も大きな値を選択します。領域内の主要な特徴が保持されるので特にエッジ部が強調され、物体の特徴が強調されます。平均プーリングにくらべ物体自体の位置が変化することに強いため、特徴が際立っているものや物体が移動している場合の予測を行いたい場合に適用します。具体的には外観検査や物体判別で多く使用します。。
一方、平均プーリングは領域内のピクセル値の平均を計算します。物体の全体的な傾向を特徴として見ることに適しています。最大プーリングに比べ、全体的な特徴での抽出を行いたい場合に適用します。具体的には動物の分類タスクなどで多く使用します。
最大プーリングと平均プーリングの選択は上記の用途を踏まえ、データの性質やタスクの要件に合わせて行います。必ずしも事前に予測した特徴をモデルが採用するとは限らないため、各プーリング手法の具体例で挙げているように「必ずこちらを使用するべき」ということはありません。予測結果や要件を踏まえてその都度選択することが望ましいです。
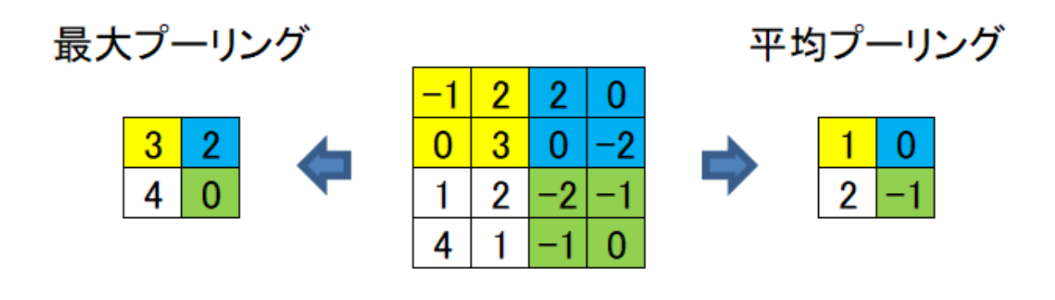
具体的な計算方法を見ていきましょう。上の図で真ん中の4×4のデータを最大プーリングすることを考えます。最大プーリングはその名の通り各色のそれぞれ最大値を抜き出し、その情報を採用します。平均プーリングは同様に各色の平均値を抜き出して採用します。
6.畳み込み層とプーリング層の積層(AlexNet)
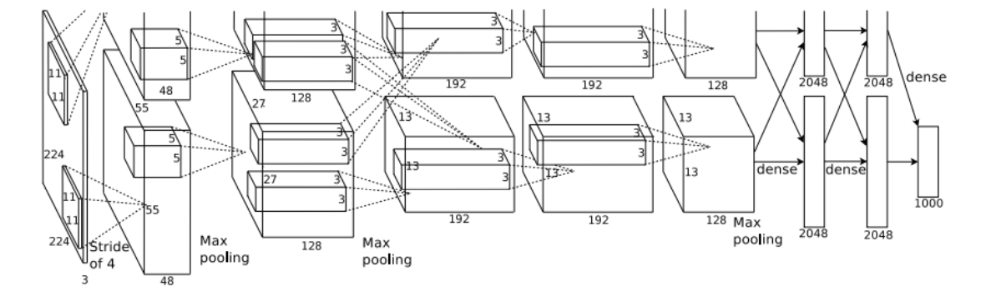
CNNを利用した有名なモデルとしてAlexNetがあります。これはILSVRCという画像認識コンペティションで驚異的な性能を発揮し有名になりました。AlexNetではCNNを重ねて画像認識精度を上げています。このようにCNNはモデル内に畳み込み層とプーリング層を積層してモデルを作成することが多くあります。
7.転移学習とファインチューニング
前項で出てきたように、CNNを積層したりすることにより画像認識精度を上げていきます。しかし、モデルが複雑になればなるほど計算に時間がかかるうえ、学習に必要なデータ量も多くなってきます。そこで用いられるのが転移学習です。
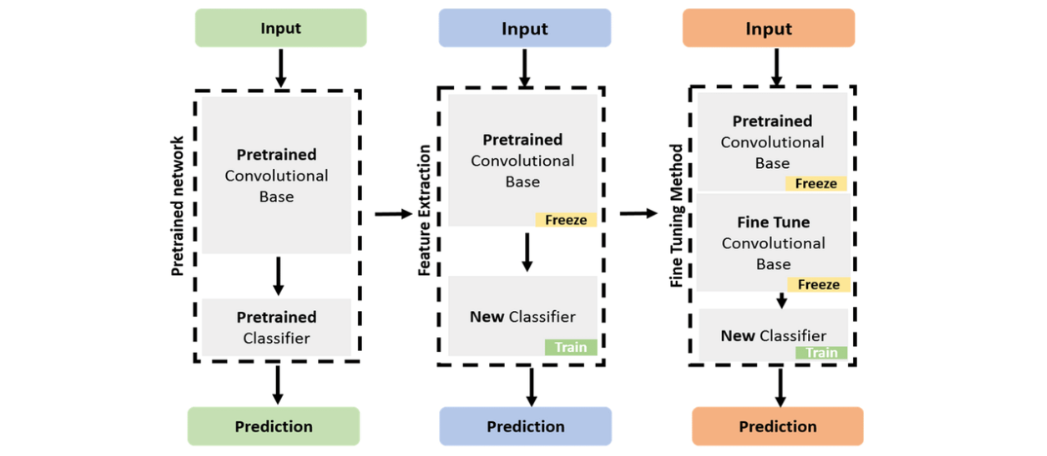
【参考:https://www.researchgate.net/figure/Concept-of-fine-tuning-and-feature-extraction_fig2_359405075】
転移学習は、あるタスクで学習されたモデルを別のタスクに適用する手法です。元のモデルは通常、大規模なデータセットで特定のタスクを認識できるように学習されています。転移学習では、このモデルの一部をファインチューニングし、新しいデータセットでわずかな調整を行うことで、モデルを新しいタスクに適応させます。
ファインチューニングは、事前学習されたモデルの一部を新しいタスクに合わせて調整する手法です。通常転移学習を行う際は公開されている学習済み公開データなどを利用することが多いと思います。このデータはモデルによって異なりますが、特定のものを認識するように学習されていますので、これを自分が認識させたい特徴を追加で学習させることにより低コストで高い認識性能をもったモデルを作成可能です。

『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
8.まとめ
CNNについて一通り見てきました。実際の実装段階では転移学習をすることが多いと思いますが、意味と成り立ちを理解することにより畳み込み計算のエラーなど理解ができる部分が増えてくると思いますので一度理解をしておくとよいと思います。