機械学習を始めると、「決定木」について聞くことがあると思います。
決定木ってなに?
どうやって実装するの?
という方に対し、決定木と結果の表示について解説していきたいと思います。

本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
決定木とは
決定木(Decision Tree)は機械学習の一つで、データを分類するためのモデルです。機械学習を勉強し始めるとよく聞く名前だと思います。
決定木は上図のようにデータを木を作るように分岐していきます。以下に決定木の特徴をあげてみます。
- 分かりやすさ:決定木はその名の通りデータを機の形に振り分ける形式で表現されるため、人間が理解しやすく結果の説明がしやすいです。
- 特徴量の自動選択:決定木は自動的に重要な特徴量を選択します。これによりモデルの解釈性が向上します。
- 過学習しやすい:決定木は過学習(overfitting)しやすいという欠点もあります。これは、モデルが訓練データに対して高い精度を示す一方で、新しい未知のデータに対してはうまく機能しないという現象です。
このように決定木は非常に解釈性に優れているため好んで使用される傾向にあります。
決定木の概要や流れに関しては
「【決定木分析完全ガイド】ポイントと実践事例を1分で解説!」
でも解説していますので併せて確認してください。

決定木の実装
データの準備
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
x = pd.DataFrame(iris.data, columns=iris.feature_names)
y = pd.DataFrame(iris.target, columns=['target'])
display(x.head(), y.head())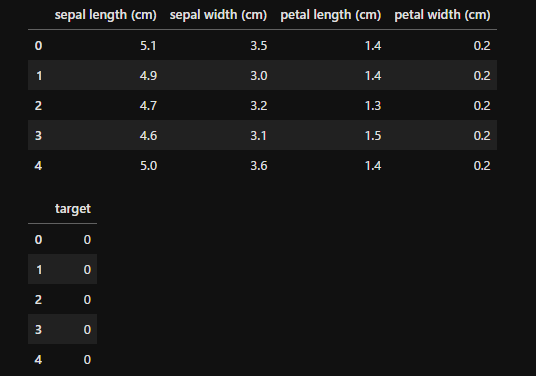
なお、通常一括でライブラリをインポートすると思いますが、今回は説明の関係上必要な部分のみimportしていきます。
今回はよく使用される「iris」データセットから、データフレーム形式のデータを作成しました。irisデータセットに関しては「【1分で理解】Pythonでの主成分分析の方法を解説!グラフ化で特徴把握」で細かく触れていますので参考にしてください。

データの分割
先ほど準備したデータを分割してトレーニング用データと検証用データに分けます。
from sklearn.model_selection import train_test_split
train_x, test_x, train_y, test_y = train_test_split(x, y, test_size=0.2, random_state=8)
display(train_x.head(), train_y.head(), test_x.head(), test_y.head())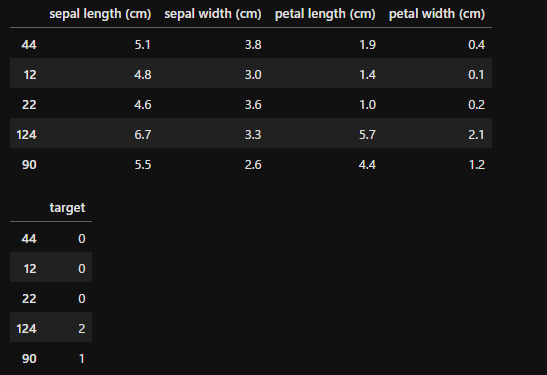
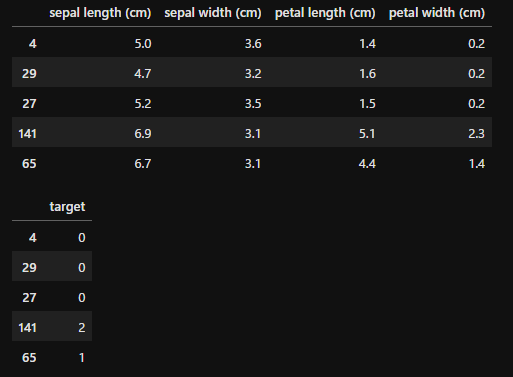
「train_test_split」で8割の学習データと2割のテストデータに分割しています。
モデルの読み込み
from sklearn import tree
model = tree.DecisionTreeClassifier(max_depth=3, random_state=8)「tree.DecisionTreeClassifier」を読み込みます。引数は、
- max_depth:決定木の木の最大深さを指定します。
- random_state:ランダムのシード値を指定します。これを合わせると再現性が出ます。
決定木は深くすると過学習になる傾向があるので、max_depthを適切に指定することにより過学習を防ぎます。気が深くなればなるほど特定の条件に縛られ、過学習気味になるということです。
モデルの学習
molde = model.fit(train_x, train_y)
score = model.score(train_x, train_y)
score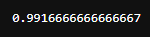
モデルの学習するためにmodelをfitします。その後、あてはまりを確認するため、scoreを計算します。
結果の見方
決定木の結果を確認していく方法を見ていきましょう。
木の構造を確認する
from sklearn.tree import plot_tree
plot_tree(model, feature_names=train_x.columns, filled=True)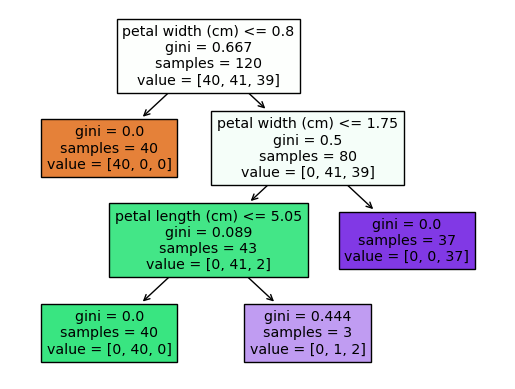
決定木が学習した内容をツリー形式で確認します。引数は
- model:表示する学習済みモデルを入力する
- feature_names:特徴量のカラム名を入力する
- filled:色を表示するかの指定
となります。各ブロックの表示内容は
- 一番上の行:分岐の条件
- gini:ジニ不純度。どれだけきれいに分割できるか。低い方がきれいに分けられている。
- samples:該当するサンプル数
- value:各クラスのデータ数
となっています。今回の例で具体的にみてみましょう。
まず、1番上は「petal width」が0.8以下のもので分割しています。0.8以下だったら2列目左側に分離されています。オレンジ色が濃いほどカテゴリの「0」ということですね。
次に、2列目右側を見ると「petal width」が1.75以下かどうかで判断しています。1.75より大きいと右側、紫のカテゴリ、カテゴリ「2」に分離されています。
このようにして、新しいデータが来た時にどのようにデータを分割するかを確認することができます。
混同行列を確認する
from sklearn.metrics import classification_report, confusion_matrix
pred = model.predict(test_x)
pd.DataFrame(confusion_matrix(test_y, pred), columns=['pred0', 'pred1', 'pred2'], index=['y0', 'y1', 'y2'])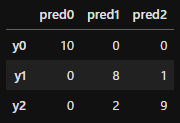
混同行列を表示します。sklearnの「confusion_matrix」を使用して表示します。
「model.predict()」でtest_xの結果を予測します。それとtest_yを比較することにより混同行列を表示します。見方は縦列に実際の正解ラベル、横軸にそれに対しての予測値を表示しています。
実際には「1」が正解のものが9個あったのに、そのうち1つを間違えて「2」と予測している、ということです。
精度を確認する
print(classification_report(test_y, pred))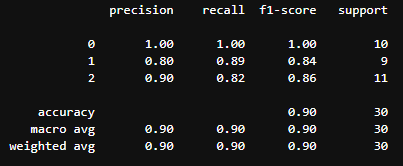
「classification_report」で精度を確認することができます。表示される内容は以下の通りです。
- Precision(適合率):適合率は正と予測されたアイテムのうち、実際に正であったアイテムの割合を示します。モデルが正と予測したものがどれだけ正確かを示します。
- Recall(再現率):再現率は実際の正のアイテムのうち、正と予測されたアイテムの割合を示します。モデルが全ての正のケースをどれだけ捉えられたかを示します。
- F1-score(F値):F値は適合率と再現率の調和平均で、これら二つのバランスを示します。F値は0から1までの値を取り、1が最良の値です。
Support(サポート):サポートは各クラスに属するサンプル数を示します。
これらの指標は、モデルがどれだけうまく機能しているかを理解するために重要です。しかし、モデルの評価は必ずどのような目的に使用するかを考えたうえで検証してください。製品検査などでは必ずしも正答率が高い方がよいとは限らず、正答率が低くても不具合を見逃さないモデルのほうが優秀であるという場合もあります。

『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
まとめ
ここまで確認したように、決定木はその直感的な理解性から多くの機械学習の問題に対する強力なツールとなります。過学習という問題を抱えているため、適切に決定木を用いてデータの分析に役立てていただければと思います。