Pythonで機械学習を始めようと思った方で、SVMをはじめにやってみる方も多いと思います。
SVMってなに?
Pythonで機械学習するときの流れって?
という疑問にお答えするため、SVMを例として機械学習の流れを見ていきたいと思います。また今回はSVMの実装を中心に解説していきたいと思います。

本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
SVMとは
SVMとはサポートベクターマシン(Support Vector Machine)という機械学習のアルゴリズムです。下の図を見てください。この図で赤色と青色の点を水色の線で分離することを考えます。この分割線に最も近い赤丸部分を「サポートベクトル」といいます。
SVMの考え方
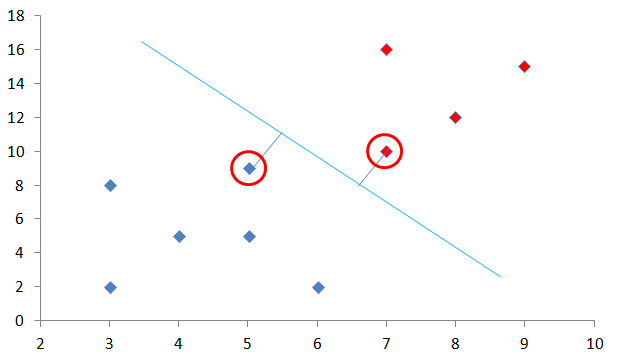
このサポートベクトルに対し下図の分割線までの距離、下図では赤い太線の部分ですが、この距離が最も最大になる水色線を考えます。この距離のことを「マージン」といいます。
マージンの最大化という言葉を聞いたことがあるかもしれませんが、このマージンを最大化する線を考えれば点群をきれいに分割できそうです。
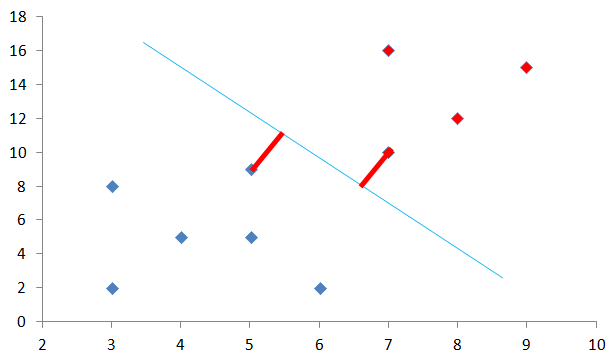
なお、今回はわかりやすくするために2次元で説明していますが、高次元でも同様に考えることにより高次元のデータにも対応できます。
非線形分離への対応
SVMは上の項目であったように直線でデータを分割する線形分離を行います。しかし、直線で分離を行わない下図のような非線形の分離であっても、データを高次元に写像することによりSVMで解析をすることが可能です。
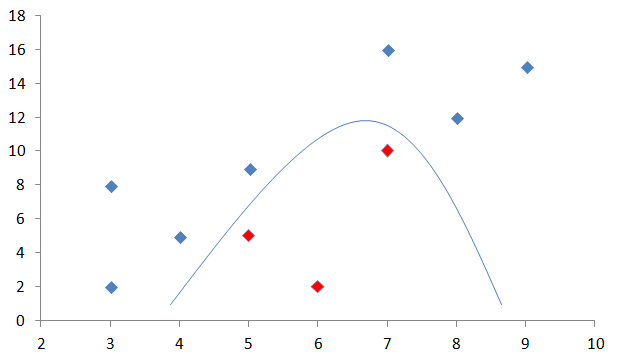
データを高次元に写像すると計算量が増えるため、カーネルトリックと呼ばれる方法を利用して式変形を行い計算量を削減しています。
このようにして非線形分離でも対応でき、精度もよいため機械学習でよく利用されるアルゴリズムになっています。
実際にPythonでSVMを動かしてみる
使用データの準備
実際にSVMを動かしてみましょう。まずはよく使用される「iris」データセットから、データフレーム形式のデータを作成しました。
なお、通常一括でライブラリをインポートすると思いますが、今回は説明の関係上必要な部分のみimportしていきます。
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
x = pd.DataFrame(iris.data, columns=iris.feature_names)
y = pd.DataFrame(iris.target, columns=['target'])
display(x.head(), y.head())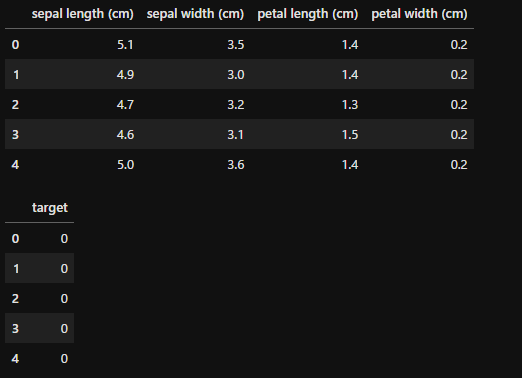
irisデータセットに関しては「【1分で理解】Pythonでの主成分分析の方法を解説!グラフ化で特徴把握」で細かく触れていますので参考にしてください。

データの分割
先ほど準備したデータを分割してトレーニング用データと検証用データに分けます。
なお、今回はのちのちの説明のため、xのうち0番目と2番目のカラムのみ使用して解析を行ったため、xのデータを「x.iloc[:,[0, 2]]」としています。分割した結果を見ていただくと特徴量が2つになっているのがわかると思います。
from sklearn.model_selection import train_test_split
train_x, test_x, train_y, test_y = train_test_split(x.iloc[:,[0, 2]], y, test_size=0.2, random_state=8)
display(train_x.head(), train_y.head(), test_x.head(), test_y.head())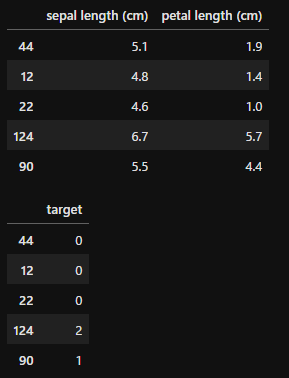

モデルの読み込み
from sklearn.svm import SVC
model = SVC(kernel='rbf', gamma='auto', random_state=8)まずはSVCをインポートします。その後、モデルを読み込みます。引数は以下の通りです。
「kernel」:使用するカーネルを設定します。モデルによって最適なカーネルが異なるので、グリッドサーチなどで最適を見つける必要があります。今回はガウスカーネルを使用してみます。
- rbf:ガウスカーネル
- linear:リニアカーネル(線形カーネル)
- sigmoid:シグモイドカーネル
「gamma」:カーネルで使用する係数
「random_state」:変数を固定するためのシード値です。これを同じにするとランダムに生成される数値が同じになるので、結果が同じになり再現性が出ます。
モデルの学習
model = model.fit(train_x, train_y)
score = model.score(train_x, train_y)
print(score)
モデルの学習をします。これは非常に簡単で、modelをfitしてやります。その後、あてはまりを確認するため、scoreを計算してみました。
結果の見方
では、予測から結果の確認までしていきましょう。
from sklearn.metrics import classification_report, confusion_matrix
pred = model.predict(test_x)
print(confusion_matrix(test_y, pred))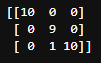
「model.predict()」でtest_xに対する結果を予測しています。その値をpredに入れ、まずは混同行列を作成してみます。
見方は縦方向が正解ラベル、横方向が予測値で、左上から順にtargetの値が0,1,2となっています。
print(classification_report(test_y, pred))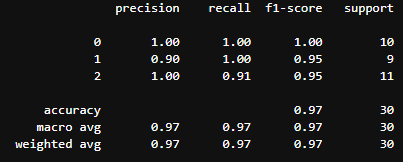
次にclassification_reportでaccuracyなどの値を確認することができます。
import numpy as np
from mlxtend.plotting import plot_decision_regions
plot_decision_regions(test_x.values, test_y.values.flatten(), clf=model)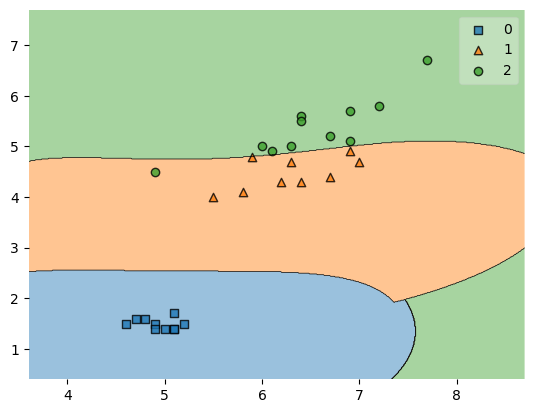
最後にSVMが各データをどのように分けているかを可視化します。
これを可視化するには「mlxtend.plotting」から「plot_decision_regions」をimportします。基本的な使い方は
plot_decision_regions(test_x, test_y, clf=「モデル」)
です。ただし、test_x、test_yともにnumpy形式である必要があるので、「.values」でnumpy形式に変換しています。またtest_yは1次元配列である必要があるため、「.flatten()」で1次元に変換しています。
この図で各カテゴリー0,1,2がどのようにSVMで分けられているかを視覚的に確認することが可能です。
また今回はSVMの実装を中心に解説していきました。SVM自体については別記事「SVMの仕組みを図で理解する!データ分析への一歩を踏み出そう」も参考にしていただけると理解が深まると思います。


『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
まとめ
今回はSVMの特にPythonでの実装を中心に見てきました。読んでいただくとわかるように、非常に簡単に使用することが可能なうえ精度が高いため、ぜひ実際に活用していただけるとよいかと思います。