最近世間でも騒がれているAI。その中でも深層学習による画像認識はいろんな分野で適用されており、注目の技術です。
そのような注目される技術がどのようなものか、知りたくないですか?
この記事では深層学習による画像認識について、その仕組みやアルゴリズムについて解説します。
また、医療分野を含めた実際の適用事例や最新の研究動向についても紹介します。

本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
深層学習とは?
深層学習(ディープラーニング)は、機械学習のアプローチで人の脳の神経回路をモデルにした、多層のニューラルネットワーク(ディープニューラルネットワーク)を使用します。
この手法は人工知能(AI)が自己学習して特徴を抽出するため、人間が特定の判断基準を設定する必要がない点が特徴です。
この技術はさまざまな分野で広く活用されており、画像認識、音声認識、翻訳などの領域で応用されています。
例えば、Facebookでは写真のアップロード時に、自動的に友達の顔を認識し、タグを付ける機能が提供されていて、この機能には深層学習の画像認識技術が活用されています。
機械学習と深層学習の違いは?
機械学習と深層学習は、人工知能の分野において、データから自動的に規則や判断基準を学習する技術です。この両者は共通の目的を持ちながらも、異なるアプローチを取ります。
データのパターン、意味、重要性をコンピュータに教え込み、与えられたデータを処理する方法をアルゴリズムによって学習させます。
この学習プロセスは、通常 “モデル” と呼ばれる概念に対して行われます。モデルは大量のデータでトレーニングされ、データをどのように解釈し、より正確な結果を出すかを学習します。
機械学習のサブセットであり、特定の手法で学習を行います。
この手法は、入力に対して重みをつけて出力を生成する「ニューロン」層が多層に重ねられたニューラルネットワーク(ディープニューラルネットワーク)が使用されます。
最も大きな違いは、機械学習がデータの特徴を人間が判断して学習を行うのに対し、深層学習は機械自体がデータの特徴を判断する点です。
つまり、機械学習では学習目的や内容に人間の介入が必要であり、効率化が可能です。対照的に、深層学習では機械が何を学ぶべきかを判断し、抽象的な問題を効率的に解決できます。
ただし、深層学習には高い精度の分析が可能ですが、大量のデータと高性能なコンピュータが必要であり、さらに学習には時間がかかるという課題があります。そのため、使用する目的や制約に応じて、機械学習と深層学習を使い分けることが重要です。
以下の記事では機械学習と深層学習の違いに焦点を当てて解説しています。

なぜ深層学習による画像認識が注目されるのか?
深層学習による画像認識が注目される理由は以下が挙げられます。
- 高精度
- 多様な応用
- 自動特徴抽出
- 大量データの活用
深層学習による画像認識が注目される理由①:高精度
深層学習は、人間の学習過程を多層のニューラルネットワークを使用してそのままコンピュータに応用したもので、複雑なパターンを学習することができます。この高い表現力と学習能力により、画像認識においても高い精度を達成することが可能となっています。
深層学習による画像認識が注目される理由②:多様な応用
深層学習による画像認識は、物体認識、顔認識、文字認識など、さまざまなタスクに対応できます。これらの技術は、自動運転、医療画像解析、製造業の品質検査など、幅広い分野で活用されています。
深層学習による画像認識が注目される理由③:自動特徴抽出
深層学習は、人間が事前に特徴を設定する必要が無く、データから自動的に特徴を抽出し、識別することが可能です。これにより、人間が見落とす可能性のある特徴もとらえることができます。
深層学習による画像認識が注目される理由④:大量データの活用
深層学習は大量のデータから複雑なパターンを学習することができます。これにより、大量の画像データから有用な情報を抽出し、高精度な画像認識を実現することが可能です。
深層学習による画像認識の仕組み
深層学習による画像認識の仕組みは以下のステップで実行されます。
- 画像処理
- 特徴抽出
- 対象物の識別
具体的には、このプロセスには主に畳み込みニューラルネットワーク(CNN)という手法が広く採用されています。CNNは、畳み込みとプーリングと呼ばれる2つの重要な操作によって構成されており、それぞれが異なる役割を果たします。
この段階では、画像の異なる領域に対して特定の関数を適用し、特徴をあらわす図を生成します。これによって、画像内の局所的な特徴が抽出され、識別プロセスに役立つ情報が得られます。
プーリング操作では、特徴を絞り込み、その領域内での最大値や平均値を取得します。これにより、データの次元が削減され、計算負荷が軽減されます。最終的には、最も情報量の多い特徴が選ばれます。
CNNは、畳み込みとプーリングを交互に行いながら構築され、その結果、画像認識だけでなく、さまざまな分野で幅広く活用されています。
以下の記事はCNNの構造や流れ、計算方法について詳しく解説しています。

①画像処理
画像処理は、コンピュータが画像を正確に認識し、適切に処理できるようにするため、画像に含まれるノイズや歪みを取り除くだけでなく、明るさや色の調整、対象物の領域を適切に切り出すことによって、機械学習モデルに適したデータを提供します。
画像のサイズ変更:機械学習モデルの入力として期待される画像サイズと実際の画像サイズが異なる場合、画像のサイズを調整する必要があります。通常、画像の横幅や縦幅を拡大または縮小します。ただし画像を拡大する場合、単にサイズを変更するだけでなく、元の画像データの周囲を0で埋める(ゼロパディング)処理が加わることがあります。
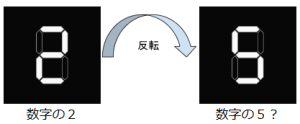
幾何的変換:画像認識において幾何的変換は重要な要素です。これには回転、平行移動、反転などが含まれます。
特に回転や平行移動を行う場合、機械学習モデルの期待する入力サイズに合わせて、画像のサイズ変更を同時に行うことが一般的です。また、反転に関しては、デジタル表示において2と5のように意味が変化する場合があるため、慎重に対処する必要があります。
スケーリング:画像データは通常、離散値(例:RGB値、0から255の範囲)を取ります。しかし、これを機械学習モデルで効果的に扱うためには、データの値の範囲を変換するスケーリングが必要です。
特に、正規化(最小値が0で最大値が1)や標準化(平均が0で分散が1)といった変換が一般的に使用されます。このようなスケーリングは、データをモデルに適した形式に整えて精度が向上します。
②特徴抽出
画像からピクセル単位(画像を構成する最小要素)で特徴を抽出してパターンを理解し、画像に何が写っているのかを認識します。
特徴抽出は、元の画像データの特徴ベクトルから、変換や選択の処理を経て予測に有用な特徴を生成するか、あるいは可視化されてデバッグしやすい基本的な特徴を取り出すプロセスのことです。
特に深層学習においては、非常に複雑な解析処理が実行されます。以前は、この処理には多大な時間がかかりましたが、近年、コンピューターの性能向上により、実用化が急速に進展しました。
深層学習の特徴の一つは、従来の機械学習で不可欠であったデータの分類に必要な情報である「特徴量の設計」が不要であることです。例えば画像認識の場合、色や形状が特徴量として考えられます。
機械学習においては、データを分類する際にどの数値に注目すべきか、その数値の範囲をどのように扱うべきかなど、事前に人間が指定する必要がありました。このため、構造化されていないデータ、例えば画像やテキストにおいては、非常に複雑な特徴量の設計が困難でした。
それに対して深層学習では、入力データがニューラルネットワーク内の「隠れ層」を経由する過程で、データの判別に必要な特徴量が自動的に抽出されます。つまり、テキストや画像などの特徴量の指定が困難なデータについてもコンピュータが自動で判断でき、人間が指定しにくい複雑な特徴を捉えることが可能となります。
③対象物の識別
対象物の識別は、事前に「ラベル」「大量のデータ」を学習させます。そして、新たに識別させたい画像を入力し、画像に何が写っているのかを識別します。
深層学習による物体検出には、以下の5つの手法が存在します。それぞれが独自の特徴を持っています。
HOG(Histogram of Oriented Gradients):画像上の物体の向きによらず変わらない特徴を認識し、画像上の物体を検出する手法。
R-CNN(Region-based Convolutional Neural Network):画像内の物体が存在する可能性の高い領域を提案し、その領域の「特微量」をCNNを用いて抽出して物体を検出する手法
YOLO(You Only Look Once):画像を矩形のグリッドに区切り、各区画にバウンディングボックス(範囲指定のための矩形)を使用することで特微量を抽出して物体を検出する手法
SSD(Single Shot MultiBox Detector):YOLOの欠点を改善するために複数の異なるサイズのバウンディングボックスを使用する物体検出の手法
DCN(Deformable Convolutional Networks):バウンディングボックスの形状を変形可能にしたことで、矩形に収めきれない異常な形状の物体の検出精度を向上させる手法
これらの手法はそれぞれ異なる特性や利点を持っていますが、共通しているのはすべてが深層学習技術に基づいており、大量のデータから複雑なパターンや関連性を学習し、新たなデータに対して高い精度で予測や識別を行うことが可能な点です。
これにより、画像認識の精度が大幅に向上し、多くの分野で幅広い応用が可能となっています。
深層学習による画像認識の活用例
深層学習による画像認識は、多くの分野で活用されています。以下にいくつかの具体的な活用例を挙げます。
- 物体認識
- 異常検知
- 画像キャプション生成
- 顔認証
- 文字認識
物体認識
物体認識とは、画像内に写っている物体の種類や位置を識別する技術です。
自動運転:自動運転技術では、深層学習を用いて道路上の他の車両や歩行者、信号などを認識し、適切な走行制御を行います。例えば、WaymoやTeslaなどの企業が自動運転技術の開発に取り組んでいます。

医療画像解析:医療画像解析では、深層学習を用いてX線やMRIなどの画像から病変や異常を検出し、診断や治療に役立てます。例えば、GoogleやIBMなどの企業が医療画像解析の開発に取り組んでいます。
異常検知
異常検知とは、データに対して正常か異常かを判定する技術です。
深層学習による異常検知では、まず大量の正常データから正常データの分布をモデリングします。次に、観測したデータが得られた正常データの分布からどれだけ離れているかによって異常を判別します。
製造業の品質検査:製造業では、深層学習を用いて製品の不良品検出に画像認識が利用されます。製品の画像を撮影し、深層学習によって学習した正常な製品の画像と比較することで、異常を検出します。
例えば、FujitsuやHitachiなどの企業が製造業の品質検査の開発に取り組んでいます。
画像キャプション生成
画像キャプション生成とは、画像の内容を自動で文章に変換する技術です。
目の不自由な人向けのサービス:目の不自由な人がスマートフォンなどで撮影した画像やインターネット上の画像を音声で読み上げる技術が利用されています。
SNSやブログなどのコンテンツ作成:SNSやブログなどで画像を投稿する際に、画像に合ったキャプションを自動で生成する技術が利用されています。
教育や研究などの学習支援:教育や研究などで画像を用いる場合に、画像の内容を説明する文章を自動で生成する技術が利用されています。
顔認証
顔認証とは、大量の顔画像を学習させ、特定の個人の特徴を細やかに認識し、その本人を高精度で認証する技術です。

スマートフォンのロック解除:スマートフォンでは、パスコード入力の代わりに顔認証が利用されています。
企業の入退出管理:企業では、従業員の入退出管理に顔認証が利用されています。
試験会場などでの本人確認:試験会場などでは、本人確認に顔認証が利用されています。
文字認識
文字認識とは、大量の文字画像を学習させ、特定の文字の特徴を細やかに認識し、その文字を高精度で認識する技術です。
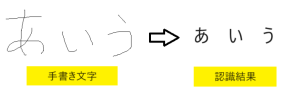
物流:手書きで書かれた配送伝票を読み取って、自動でシステムに入力がされています。
金融や保険:確認する項目の多い新規の申込書類や審査申込書などのデータ化を行います。
工場:毎日多くの受発注が発生する工場でも、大量の書類の入力に役立っています。
深層学習による画像認識の最新研究動向
深層学習による画像認識の最新研究動向については、以下のようなトピックがあります。
新たなネットワーク構造と学習方法
深層学習の発展に伴い、新たなネットワーク構造や学習方法が生み出されています。これらの新たな方法は、画像認識の精度を向上させるために重要な役割を果たしています。
全体最適化に相当する計算
畳み込みニューラルネットの最近の適用事例の中には、従来のパターン認識では説明し難い、全体最適化に相当する計算を行っているものがあります。これは、深層学習が複雑な問題を解決する能力を示しています。
画像生成と物体検出
画像生成では、画像や乱数を基に新たな画像を生成します。物体検出では、画像内に指定した物体があれば四角形で領域を指定します。これらのタスクは、深層学習の表現力の高さを示しています。
最適化アルゴリズム
最近では、「Sharpness-Aware Minimization(SAM)」という新たな最適化アルゴリズムが提案されました。この手法は、深層学習モデルの訓練をより効率的に行うことを可能にします。

データサイエンスを学習するならTech Teacherで!

『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
深層学習を用いた画像認識の仕組みと活用事例まとめ
この記事では、深層学習を用いた画像認識の仕組みと活用事例について紹介しました。深層学習を用いた画像認識は現在さまざまな分野で活用されており、これからもますます発展する分野です。この記事の内容を参考に、現在の技術内容の理解を深め、今後の技術発展の一端を担ってみてはいかがでしょうか。