データサイエンスを学習の方で、以下のようなことを感じている人はいませんか?
・「機械学習の最適化アルゴリズム」を学習したが、よくわからない
・「機械学習の最適化アルゴリズム」のイメージを掴みたい
このような方に向けて、難しい数式を一切使わず、直感的に理解できるように「機械学習の最適化アルゴリズム」を解説しています。
「最適化アルゴリズムを初めて学習する方」や「難しい数式を追うのが苦手な方」は是非ご覧ください。
本記事を読めば、「機械学習における最適化アルゴリズム」について理解することができます。

本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
機械学習の最適化アルゴリズム 基本知識

機械学習の最適化アルゴリズム 基本用語
「最適化アルゴリズムを理解するための基本用語」について確認していきましょう。
本記事で紹介する基本用語の種類は以下の通りです。
- 最適化
- アルゴリズム
- 機械学習
- 損失
- ニューラルネットワーク
- 学習率
最適化
最適化は、「特定の条件を満たす中から、最適な解を選び出す」という問題に対して数学的にアプローチをすることです。
(例)実験などで、データをプロットした。
このプロットに対して、適切な直線引きたい場合。
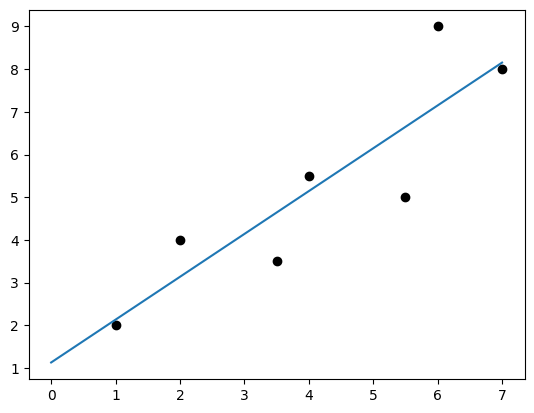
今回は、回帰分析の中でも基本的な方法である最小二乗法を使用しました。
最小二乗法を使用すると、下図のような直線が引けます。
アルゴリズム
アルゴリズムとは、ある特定の問題を解く手順を、単純な計算や操作の組み合わせとして明確に定義したものです。
(例)料理の作業手順や、音楽の楽譜のようなものです。
コンピューターに対しては、処理を行うために人間がプログラミングで命令をしています。
機械学習
機械学習とは、人工知能の分類の1つで、効率的かつ効果的にコンピューターが学習を行うための理論体系を指します。
機械学習では、適切な処理を行えば、入力されたデータを元に数値を予測したり最適化したりできるため、さまざまな分野で活用されています。
機械学習は、スマートフォンのロックロック解除などに使われる「顔認証機能」、ユーザー1人1人にAIが相性の良い商品やサービスをおすすめしてくれる「レコメンド機能」など私たちの身近に溢れています。
損失
損失とは、コストとも呼ばれ、モデルによる予測と結果の差のことを言います。
損失の値を最小化することで、機械学習モデルの最適化が実現します。
損失関数は、「2乗和誤差」や「交差エントロピー誤差」など状況に応じて、設定します。
ニューラルネットワーク
ニューラルネットワークとは、人間の神経細胞(ニューロン)を数理的にモデル化したアルゴリズムです。
学習率
学習率は、最適化において、重みパラメータを一度にどの程度変化させるかを表すハイパーパラメータのことです。
イメージは、「今いる位置から、どの程度移動するか?」を表している量です。
学習率が小さすぎると、目的地に辿り着くのに時間がかかってしまいます。
一方、学習率が大きすぎると、目的地を通り過ぎしまいます。
そのため、適切な学習率を設定しなければなりません。
最適化アルゴリズムの目的
最適化アルゴリズムは、実社会にとても役に立つ分野です。
最適化アルゴリズムの目標は、「最適化問題」を解けるような手法を考案し、更に効率よく解けるように改良していくことです。
効率よく解くことは、計算スピードに大きく関わり、コンピューターに実行させる際に重要となります。
最適化問題では、「必要な栄養素を確保する食事メニューの中から、最小カロリーとなっているメニューを選び出す、などのようなダイエット問題を数学でどのように解くか?」といった非常に身近な問題を取り扱います。
機械学習において、最適化アルゴリズムは、「機械学習を行う際に伴う損失を限りなくゼロにする」ということを目的にしています。
損失をゼロにすることで効率よく機械学習が行えるようになるため、性能の高い人工知能(AI)の開発が可能になります。
最適化アルゴリズムの種類

最適化アルゴリズムには、さまざまな種類があります。
ここでは、それぞれの「機械学習の最適化アルゴリズム」ついて、難しい数式を一切使わず、直感的イメージで理解できるように解説します。
本記事で紹介する最適化アルゴリズムの種類は以下の通りです。
- 最急降下法
- SGD
- ミニバッチ学習SGD
- モーメンタム
- AdaGrad
- RMSProp
- Adam
最急降下法
最急降下法とは、「損失関数を微分し、最も勾配の急な方向に下っていき、損失関数を小さくする手法」です
言い換えると、「今いる位置において、最も斜面が大きい方向に下っていくアルゴリズム」です
最急降下法は、「局所的に最も損失関数を小さくする向きに移動するが、大局的には効率の良い方法ではない」という点に注意が必要です。
更に、最急降下法にはいくつか欠点があります。
・局所解で止まる
・全てのデータを一度に扱うため計算量が多く遅い
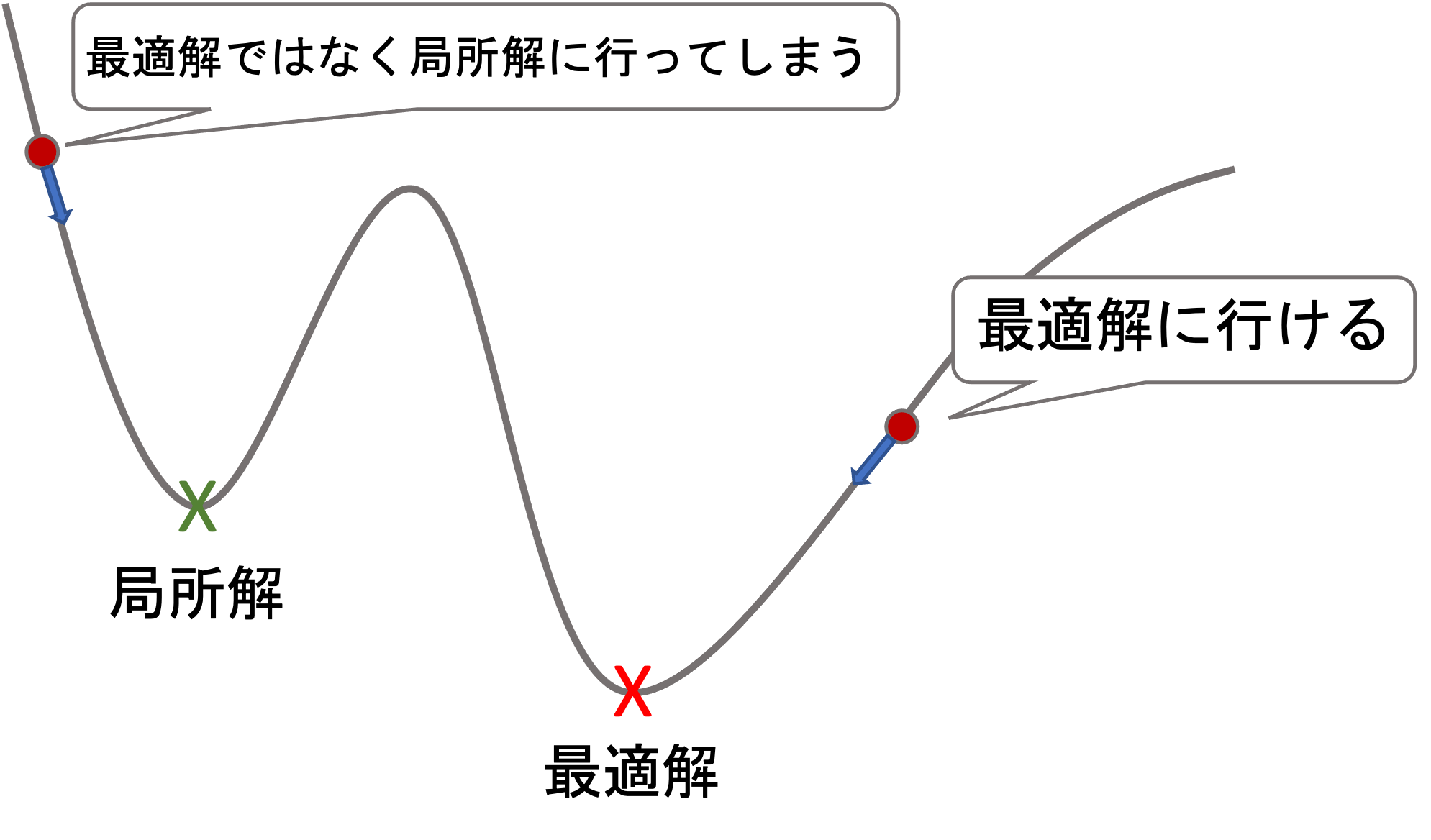
引用:https://datawokagaku.com/gradient_descent/
最急降下法は、最も基本的な最適化アルゴリズムです。
更に、これから紹介する他の最適化アルゴリズムは最急降下法の欠点を補うために生まれた派生的なものです。
そのため、詳しく学んでいく方は、まず「最急降下法」を理解するようにしましょう。
SGD
SGDは「Stochastic Gradient Descent」の略で、日本語では確率的勾配降下法と言われています。
SGDは、先ほど解説した最急降下法にとてもよく似ています。
最急降下法との違いは、『ランダム性を追加』したことです。
方法としては、一回のパラメータ更新で1つのデータのみをランダムで使います。
そのため、最急降下法のように局所解で抜け出せなくなったとしても次のパラメータ更新により、脱出できるようになります。
SGDの欠点は、1つのデータのみをランダムで計算していくため、並列計算ができず、時間がかかってしまうことです。
ミニバッチ学習SGD
ミニバッチ学習とは、1つのサンプルを使用して勾配を計算する『バッチ学習』とは異なり、複数のサンプルをひとまとめにしてパラメーターを更新する手法です。
これまで学習した「最急降下法」や「SGD」はバッチ学習にあたります。
そして、ミニバッチ学習SGDは、最急降下法の並列計算とSGDのランダム性を合わせた計算方法で最適化アルゴリズムを行います。
1回のパラメータ更新で複数の定数をランダムに並列計算していきます。
そのため、最急降下法のように極小値で抜け出せなくなることがなく、SGDのように時間がかかることもありません。
しかし、ミニバッチ学習SGDを利用すると、Pathological Curvatureというくぼみにはまってしまいオーバーシュート(一度の更新が大きすぎると起きる振動)を起こし、時間がかかってしまう場合があります。
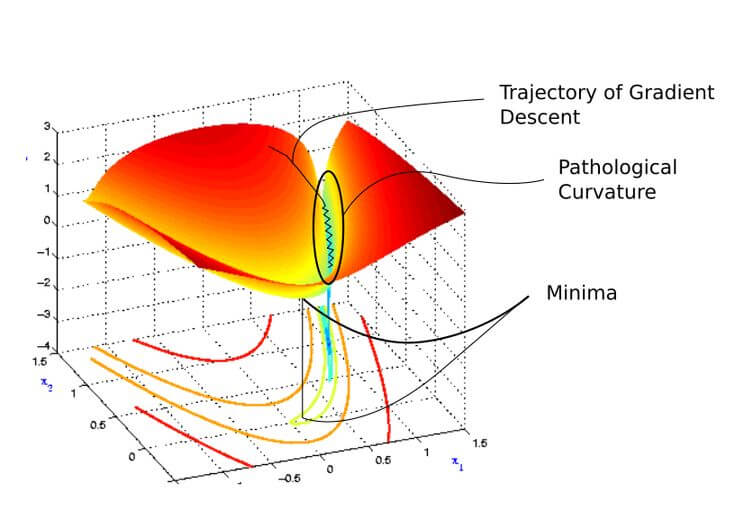
引用:https://www.pinterest.jp/pin/pathological-curvature–568649890446799273/
モーメンタム
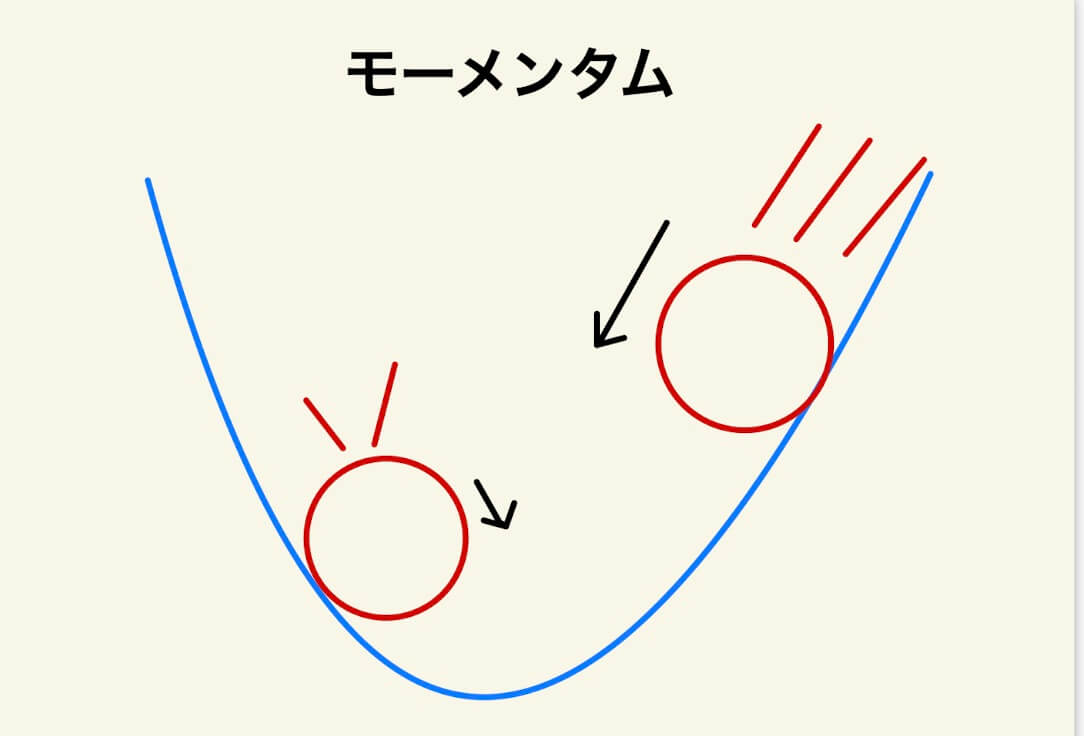
モーメンタムとは、SGDに「運動量(Momentum)」を導入した手法です
「斜面で物体が転がり落ちる」概念を利用しています
運動量
(運動量) = (物体の質量) × (物体の速度)と定義されています。
この運動量は、一般的に「運動の激しさを表しています。」
すなわち、「重くて、速い物体ほど、運動の勢いがある」ということを表しています。
『最急降下法やSGD』と『モーメンタム』の違い
モーメンタムは「斜面で物体が転がり落ちる」概念を利用していると紹介しました。
最急降下法やSGDでは、「今いる位置において、最も斜面が大きい方向に下っていくアルゴリズム」です。
したがって、「損失関数の形」と「今、どこにいるか?」に注目します。
一方、モーメンタムでは、「損失関数の形」と「今、どこにいるか?」に加えて、「運動量(主に速度)」に注目します。
「運動量(主に速度)」を導入することで、
・谷底から遠く、勾配が大きい場所➡️最小値に向かって大きく進む
・最小値が近づいて、谷底付近では勾配が小さい場所➡️最小値に向かって少しずつ進む
を実現し、効率的に学習を進められるようになりました。
モーメンタムを利用することで、Pathological Curvatureにはまりオーバーシュートによる振動を起こすことを抑えることができます。
AdaGrad
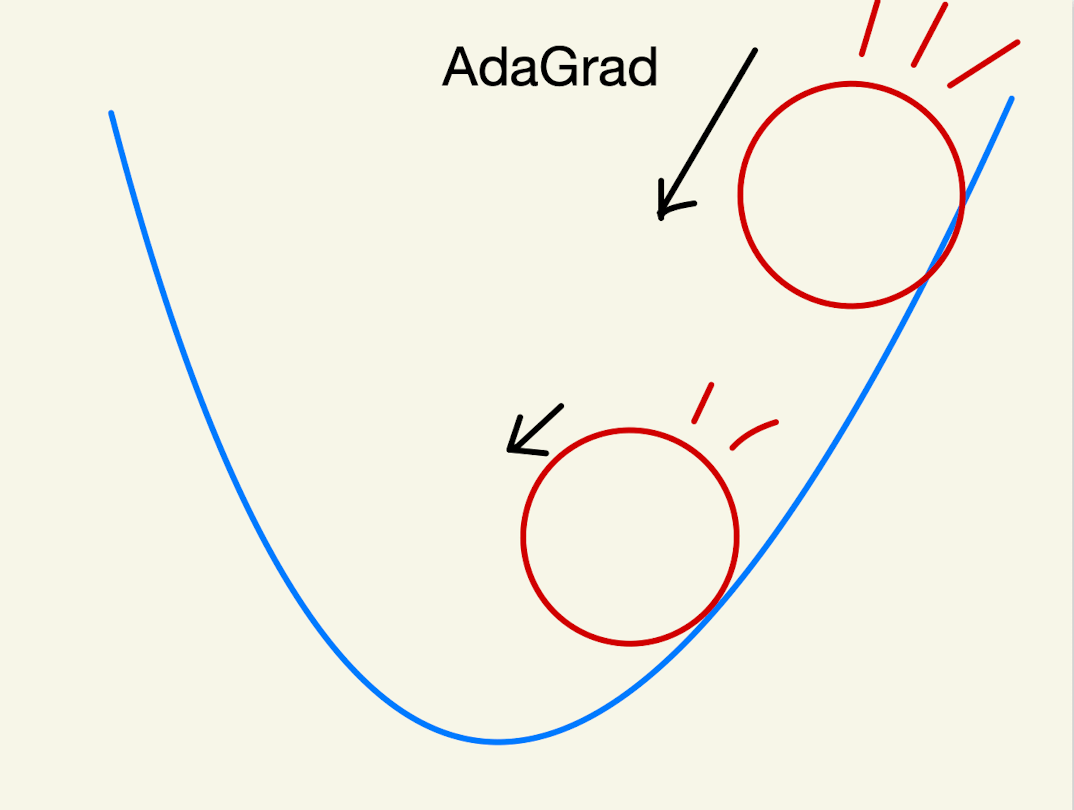
AdaGradは、「Adaptive Gradient Algorithm」の略で、翻訳すると「適応型勾配アルゴリズム」です。
AdaGradは、学習率を調整しながら、損失関数を最小にしていく手法です。
最急降下法やSGDでは、最小値付近で、斜面を行ったり来たりして、非効率的な探索となっています。
モーメンタムでは、「運動量」を導入することで、斜面を行ったり、来たりする回数を少なくすることに成功しました。
AdaGradは、
・初めの段階では学習率を高くする。➡️最小値に向かって大きく進む
・最小値に近づいて、学習率を調整➡️最小値に向かって少しずつ進む
この結果、斜面を通り過ぎることをなくしました。
AdaGradもモーメンタム同様、SGDの際にPathological Curvatureのオーバーシュートによる振動を抑えるために利用します。
RMSprop
RMSpropは、 AdaGradを改良したアルゴリズムです
具体的には、AdaGradの考え方に加えて、過去に更新したパラメーターより直近のパラメータに注目して学習率を調整しています
RMSpropも同様、SGDの際にPathological Curvatureのオーバーシュートによる振動を抑えるために利用します。
Adam
Adamは、モーメンタムとRMSPropの良いところを組み合わせた手法です。
「運動量」と「学習率の調節」により、Pathological Curvatureのオーバーシュートして振動することを抑制します。
Adamは、現在最適化アルゴリズムで多く利用されています。
まとめ
- 最急降下法…最も勾配の急な方向に下っていく手法
- SGD…「最急降下法」+ランダム性
- ミニバッチ学習SGD…複数のサンプルをひとまとめにしたSGD
- モーメンタム…「運動量」の概念を導入
- AdaGrad…「学習率」の調整を行う
- RMSProp…AdaGradの改良
- Adam…「モーメンタム」+「RMSProp

『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
今後の学習

機械学習の最適化アルゴリズムについて理解するためには、専門的な知識やスキルが必要不可欠です。
しかし、具体的にどのような知識やスキルが必要なのか分からない方もいると思います。
本記事で、最適化アルゴリズムの概要やイメージを掴むことができた方に向けて、「今後、学習する内容」について紹介します。
最適化アルゴリズムに必要な知識やスキルは以下の通りです。
1.数学的に理解する
2.プログラミングを習得する
1.数学的に理解する
数式を追うだけでなく、直感的イメージで物事を理解することは最適化アルゴリズムに限らず非常に重要なことです。
しかし、直感的イメージだけでは「誤解」や「曖昧さ」が残ってしまい、完全な理解はできません。
そのため、数学を通して、最適化アルゴリズムをより厳密に理解するようにしていきましょう。
最適化アルゴリズムを理解するためには、漸化式など高校数学で学習する幅広い分野での知識が必要です。
さらに、大学の教養レベル以上の確率や統計、微分積分、アルゴリズムや解析モデル、線形代数の知識も必要となります。
2.プログラミングを習得する

最適化アルゴリズムを理論的に理解できた方は、コンピューターで実装させましょう。
最適化アルゴリズムを実装する際には、プログラミング言語の知識が必要です。
アルゴリズムを適切に実装することで、計算速度を改善したり、最適解の精度を向上させたりすることができます。
最適化アルゴリズムを実装する際のプログラミング言語は、「Python」、「C言語」、「Julia」が本やインターネットで情報が集めやすくておすすめです。