

データ分析に便利なヒートマップを簡単に作成できないかと考えたことはありませんか?Pythonのseabornライブラリを利用すると、数行で簡単に相関係数の表が作れますので、使い方とカスタマイズ方法について見ていきましょう。

本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
ヒートマップとは
ヒートマップとは、データ関連度合いを色の違いで表現する可視化の手法です。数値が大きい場所ほど色が濃くなったり、数値が小さい場所は薄い色で表示されるので、データの特徴を一目で把握できるようになります。
身近な例として、ある地域の気温や降水量、人口密度などのデータを地図上に重ねて示す表を考えてみましょう。気温のデータであれば北部地方は寒色、南部地方は暖色で示されることから、地域ごとの気温がどのような傾向があるかを理解しやすくなります。
このように、ヒートマップを使うと大まかな数値の分布や傾向を把握しやすくなりますが、細かい数値までは読み取れないため、あくまで全体像の把握を目的として利用します。
Pythonのデータ可視化ライブラリの1つであるSeabornには、手軽にヒートマップを作成できるheatmap()という便利な関数があり、これを使うことで簡単に色分けされたヒートマップを作ることができます。
ヒートマップの作成やカスタマイズ方法を知る前に、まずはデータ分析に利用される関連したライブラリをいくつか確認してみましょう。
データ分析関連のライブラリ
NumPy
NumPyはPythonで大量の数値データを効率よく処理するために利用される最も基本的なライブラリです。ndarray型の数値配列を作成するプログラム例をいくつか見てみましょう。
import numpy as np
# 1次元配列
data = np.array([1, 2, 3, 4])
# 全要素が0の配列
zerodata = np.zeros((3, 3))
# ランダムな値で初期化
randdata = np.random.random((2, 4))
print(randdata)
"""
出力結果の例:
[[0.21750375 0.3985896 0.88238956 0.4167311 ]
[0.97083369 0.46134491 0.32243053 0.40327047]]
"""このように、NumPyではさまざまな方法で簡潔にndarray配列を構築できるのが大きな特徴です。データの可視化に利用されるmatplotlibライブラリで描画時にこの配列型を直接渡せば、ヒートマップや他の多くのグラフを描画できます。
Pandas
Pandasは表形式のデータや時系列データを扱うための基本ライブラリです。Excelのような表形式のデータを読み込んでデータフレームという表構造のデータに変換したり、集計や次元削減などの処理を行なったりすることができます。
データフレームの作成例は以下のようになります。
import pandas as pd
# 気温が保存されたCSVデータの読み込み
df = pd.read_csv('data.csv')
# 日較差を新しい列として追加
df['日較差'] = df['最高温度'] - df['最低温度']
print(df['日較差'])
"""
出力結果の例:
0 5.1
1 6.0
2 6.6
3 7.2
4 7.1
Name: 日較差, dtype: float64
"""この例では、地域ごとの最高温度と最低温度が保存されたCSVファイルから、その差である日較差を計算して、新しい列として追加する処理が実装されています。Pandasはデータサイエンス分野には必須とも言えるライブラリなので、使い慣れておきましょう。
Matplotlib
Matplotlibは、Pythonでさまざまな種類の静的なグラフを描画するためのライブラリです。Excelのグラフのように、線グラフや折れ線グラフ、散布図やヒストグラムなどのグラフを描画できます。
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
matplotlib.rc('font', family='sans-serif')
# 平均0, 標準偏差1の正規分布から10万件の乱数を生成
data = np.random.normal(0, 1, 10**5)
# ヒストグラムをプロット
plt.hist(data, bins=50)
# タイトルとラベルの設定
plt.title("standard normal distribution")
plt.show()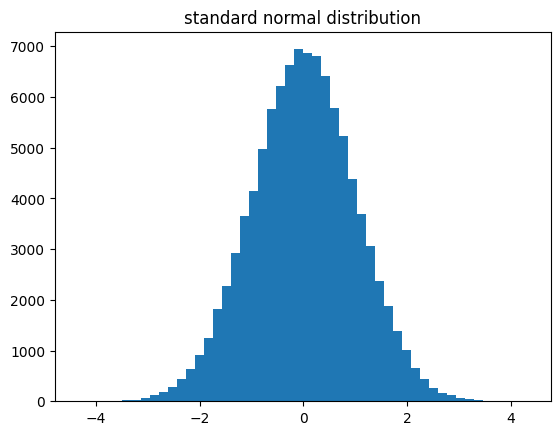
上記のコードは、標準正規分布に従う乱数をNumPyで10万データ分生成し、ヒストグラムとして描画するものです。グラフのタイトルが正しく表示されない場合があるため、冒頭でフォントの設定を記述しています。データの件数を調整して、数が多いほど正規分布に近づくことを確かめられますね。
Seabornとは
SeabornはPythonのデータ可視化ライブラリで、Pandasなどで読み込んだデータを様々なグラフに表すことができます。matplotlibライブラリをベースに作られ、簡単な指定で綺麗なグラフが作成可能です。
基本的な使い方
慣例として、Seabornライブラリをsnsという名前でインポートします。
import seaborn as sns
描画できるグラフの種類はいくつもあるので、今回は折れ線グラフと散布図を描画するコード例を確認しましょう。
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# numpyでデータ生成
x = np.random.normal(loc=0, scale=1, size=10**3)
y = np.random.normal(loc=0, scale=1, size=10**3)
# データフレーム作成
df = pd.DataFrame({"x": x, "y": y})
fig, axes = plt.subplots(ncols=2)
# ヒストグラム
sns.distplot(x, bins=15, ax=axes[0])
# 散布図
sns.scatterplot(data=df, x="x", y="y", ax=axes[1])
plt.tight_layout()
plt.show()
NumPyで標準正規分布に従うデータx, yを生成し、それをPandasのデータフレームに変換してから、Seabornで2種類のグラフを描画します。横並びに整えて描画するために必要なのはグラフ上での軸を指定することです。このように表を自由にカスタマイズする方法がいくつかあります。
ヒートマップの作成
今回は沈没したことで有名なタイタニック号の乗客に関する情報を集めたデータセットを利用しましょう。データはSeabornライブラリを使ってダウンロードできるため、事前の準備の必要がなく、簡単に実行できます。
titanicデータセットは乗客とクルーの性別や年齢、配偶者や子供の数、チケットの料金などの情報からその乗客が生存したかどうかを予測するタスクで用いられ、機械学習の分野における登竜門として有名です。データの特徴を把握するためにSeabornライブラリでヒートマップを作成することが役立ちます。
import seaborn as sns
df = sns.load_dataset("titanic")
table = df.pivot_table(
index="sex",
columns="class",
values="survived",
aggfunc="sum"
)
sns.heatmap(table, annot=True)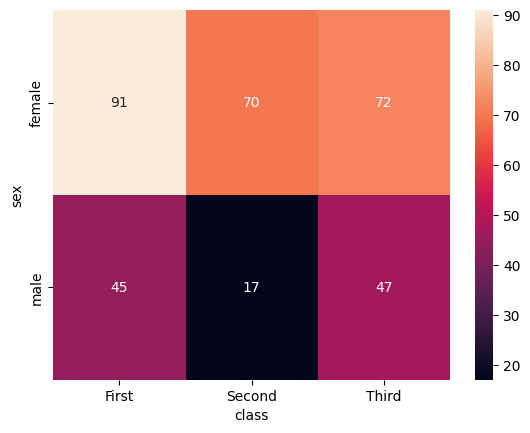
pivot_table()では、dfの1人の乗客のデータごとに性別(sex)とチケットのクラス(Ticket)で集計し、生存者数(survived)の総数を表示しています。ヒートマップを利用することで、データの傾向が一覧で理解できますね。
カスタマイズ方法
SeabornはMatplotlibをベースとしたライブラリなため、表のカスタマイズも同様に設定できます。まずは、表のタイトルと軸名を挿入する方法についてコード例を見てみましょう。
import seaborn as sns
import matplotlib.pyplot as plt
df = sns.load_dataset("titanic")
table = df.pivot_table(
index="sex",
columns="class",
values="survived",
aggfunc="sum"
)
ax = sns.heatmap(table, annot=True)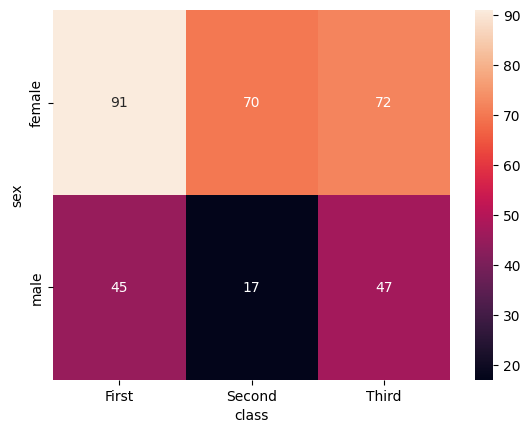
次に、heatmapメソッドで引数のcmapを指定することで色調を変更してみます。ヒートマップという名前ではありますが、冷たい色への調整も可能です。
sns.heatmap(table, cmap="YlGnBu", annot=True)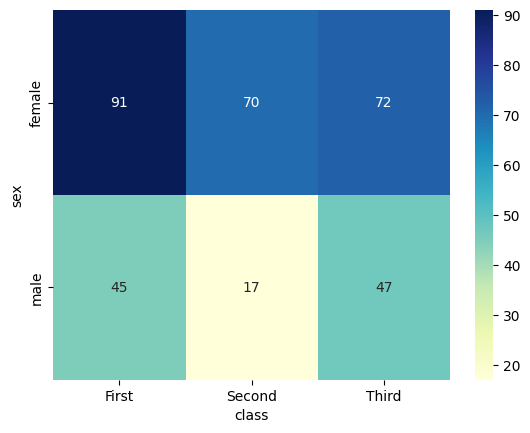
matplotlibをベースとしたライブラリであるため、タイトルや軸のラベルは次のようなコードで付与できます。
plt.title("Number of Survived Passengers")
plt.xlabel("X - Class")
plt.ylabel("Y - Sex")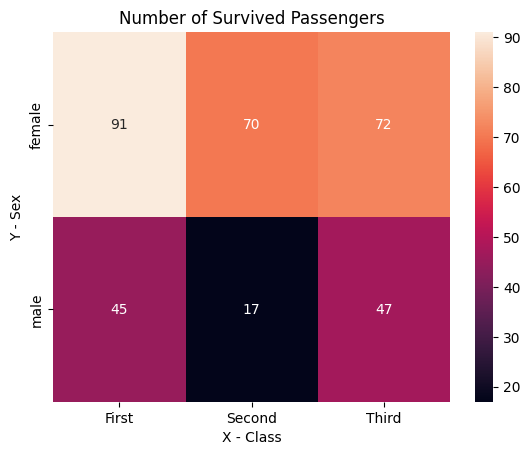
特定のセルの文字色を変更したい場合、ax.textsから要素を取得し、set_color()を利用して直接設定しましょう。
text_objs = ax.texts
text_objs[0].set_color("red")
text_objs[4].set_color("yellow")
plt.show()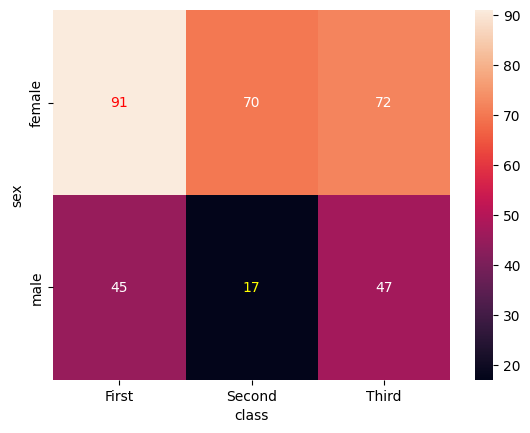
特定のヒートマップだけ、スタイルを変更するにはwith文を使いましょう。文字の大きさを20、文字の太さを”bold”に設定した条件下でのヒートマップを表示させます。
with plt.rc_context({"font.size": 20, "font.weight": "bold"}):
ax = sns.heatmap(table, annot=True)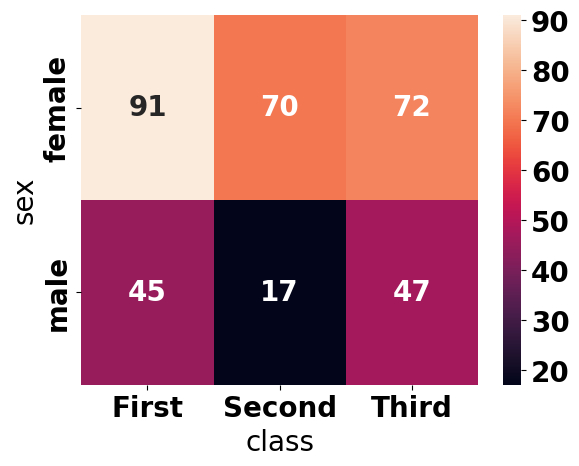
他にも、グリッド線の色と幅を調整したり、刻み目の間隔を設定したりすることなどが引数の指定で実装できます。ライブラリが更新されるたびに指定方法は異なるため、公式ドキュメントを参考にしてみましょう。

『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
まとめ
Seabornライブラリでヒートマップを作成するにはPandasやMatplotlib等のデータサイエンスに関連したライブラリに使い慣れておくことが大切です。カスタマイズ方法を知ると、自分好みのヒートマップを作成できるため、引数指定の方法を公式ドキュメントを参考にして実装してみてください。





