


本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
クラスタリングの概要
データサイエンスやビジネスシーンでよく用いられるクラスタリングとは、クラスタ解析やクラスター分析とも呼ばれるデータ解析手法の一つで、統計学では多変量解析に含まれます。
クラスターというのは、特定のグループを表す単語です。
そのため、クラスタリングとは大量にあるデータを、データ同士の特徴や傾向などの類似度で特定のグループにわけることを指します。
例えば、アンケートや市場調査で得たデータを解析する場合には、質問と回答しかわかりません。クラスタリングを用いれば、質問と回答から類似したグループを予想することが可能となります。
類似したグループを把握することで、新商品のセールスをどういったグループに行うべか、各グループはどういった特徴があるのか、などのマーケティングに役立てることができます。
クラスタリングの活用例として、購買情報を元にしたグループ分けで考えてみましょう。
購買情報から、
・高級品志向グループ
・流行品グループ
・低関心グループ
・節約グループ
などといったグループ分けが可能となります。
各グループに同じ内容のダイレクトメッセージやミスマッチな商品のおすすめをしても売り上げは増加しないと予想できますよね。
それぞれのグループに合った商品をセールスをすることで、売り上げ増加に寄与することができるようになりますね。
このようにクラスタリングはマーケティングに活かすことができ、
・顧客の購買情報から新商品や類似商品のおすすめ
・顧客情報に合わせたダイレクトメッセージの配信
などに用いることができます。
一方で注意点もあり、クラスタリングではただ単にグループ分けを行うわけではありません。
クラスタリングでは正解がわからない状況で、実際のデータを基にグループ分けを行っていくため、各グループの解釈は後から行うことになります。
そのため、解析結果の解釈を行うには、データサイエンスの知識をもった人間が必要と言えるかもしれません。また、「グループ分けを行う」ということから、分類と混同しやすいのが注意点です。
分類とは、どのグループに属するかあらかじめ答えが用意されています。これを教師あり学習と呼びます。それに対して、クラスタリングは教師なし学習の1種です。
教師あり学習というのは、正解がわかりきっているデータを学習する手法のことを指し、教師なし学習というのは、クラスタリングのように正解がない状態でデータ学習する手法のことを指します。
クラスタリングの手法

クラスタリングの手法にはいくつかありますが、大きく分けると、
・階層的クラスタリング
・非階層的クラスタリング
にわけられます。
階層的クラスタリングは、特定の商品や分析データをあらかじめ定めている場合に用いるのが一般的です。
それに対して、非階層的クラスタリングは、不特定多数のビッグデータを分析する場合に用いるのが一般的です。分析目的を明確にしておくことで、両者を使い分けることができます。
クラスタリングのメリット
クラスタリングを用いることで、大量にあるデータを簡潔にまとめ、解析の考察をしやすいというメリットがあります。
類似したデータを各グループにまとめていくので、各グループの特徴やデータの傾向などを把握するのにも向いています。
階層的クラスタリングについて
階層的クラスタリングとは、最も類似している・類似していないデータ同士を1つずつ順番にグループ分けしていく手法になります。
1つ1つのデータを比較して、類似している場合には同一グループにわけていきます。
これをデータがなくなるまで繰り返すことで、最終的にはデンドログラムと呼ばれるグラフが完成します。
デンドログラムでは、どのデータ同士が類似しているかがわかりますが、データ同士が低い位置で合流している場合には、類似性が高く、高い位置で合流している場合には、類似性が低いと読み取ることができます。
また、データをどの高さで区切るかによって、グループ数とグループに属するデータの数が変動します。
デンドログラムの例
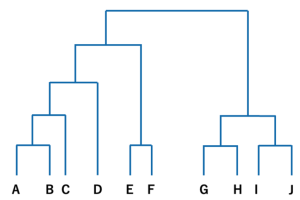
階層的クラスタリングでは、データを1つずつ順番にグループ分けをしていくため、あらかじめグループ数を決めておく必要がないのが特徴です。
そのため、グループ数をあらかじめ決めることができない場合などに用いられます。
階層的クラスタリングの手法はいくつかあります。
ウォード法
ウォード法は、それぞれのデータから平方和を算出し、平方和が小さいものからグループを作っていく手法です。外れ値に弱いですが、明確な分類結果が得られる最も一般的な手法とされています。
群平均法
群平均法は、2つのグループを構成するデータの全ての組み合わせの距離を算出し、その平均をグループ間の距離とする手法です。群平均法では、全てのグループ間の距離を平均するため、外れ値に強く、最短距離法と最長距離法の中間の分類結果が得られる手法です。
最短距離法
最短距離法は、群平均法と同様に、データ間の距離を算出します。その中で一番距離の近い組み合わせを選び、その値をグループ間の距離として考える手法です。外れ値に弱く、分類感度が低いのが特徴です。
最長距離法
最長距離法は、最短距離法とは逆の手法になります。一番距離の遠い組み合わせを選び、その値をグループ間の距離として考える手法です。外れ値に弱いが、分類感度は高いのが特徴です。
どの手法を選ぶかといった規則はなく、試行錯誤しながらより良いグループに分けることができる手法を選択していくのが現状です。
迷った場合には、最も一般的な手法であるウォード法を選択するといいですね。
階層的クラスタリングはデータ数が100以下の場合に用いることが勧められています。
非階層的クラスタリングについて
非階層的クラスタリングとは、階層的クラスタリングに対して、階層を作らずにグループ分けしていく手法を指します。そのため、デンドログラムは作られず、分けられたグループのみが結果として得られます。
1つのデータの塊を、指定した数のグループに分けていくため、ビッグデータなどのデータ量が大量にある場合の解析などに用いられます。
しかし、非階層的クラスタリングでは計算量が膨大なため、処理時間が長くなってしまうのが欠点です。
また、最適なグループ数を算出する方法が確立されておらず、指定するグループの数は解析者の主観になってしまいます。
非階層的クラスタリングのイメージ図

非階層的クラスタリングの手法には、
・k-means法
・x-means法
・超体積法
・混合正規分布
が挙げられます。
k-means法
k-means法ではデータをあらかじめ決めておいた数にグループ分けし、その後、各データとグループの重心の距離が、他のグループとの重心より小さくなるようにデータを再配置していく手法になります。
x-means法
x-means法では、k-means法のようにあらかじめグループ数を決めておかなくても、最適なグループ数を算出してくれる手法になります。しかし、分類感度は低いと言われています。
超体積法
超体積法では、点集合を凸多面体の集まりとみなし、その体積を最小にすることで、最適なグループ分けを見つけていく手法になります。
超体積法自体がグループ数を決める手法になることもあります。
混合正規分布
混合正規分布では、各グループに対応する多次元の正規分布からデータが作られていると仮定します。その後、確率分布を求めることによりデータをグループ分けする手法です。
非階層的クラスタリングはデータ数が300以上の場合に、用いることが勧められています。
データ数が100〜300程度の場合には、階層的・非階層的クラスタリングを併用することが勧められているので、データ数に応じて手法を選択していくといいですね。

独学でクラスタリングをはじめよう
独学でクラスタリングをはじめる場合には、まずは機械学習について学ぶことがオススメです。
クラスタリングは機械学習の中の教師なし学習に含まれます。
そのため、機械学習について知識があれば、クラスタリングの理解が深まりやすいです。
実際にクラスタリングを行う際には、pythonを使うことで簡単に行うことができます。
pythonを使ってクラスタリングを行う場合には、scikit-learnと呼ばれるライブラリを使用するので、scikit-learnについて学習しておくことで、独学でクラスタリングをはじめることができます。
解析を行う際のサンプルデータはバークレー大学のリポジトリーで購買情報が公開されているため、そちらをダウンロードして使用することで、クラスタリングを行うことができます。
そのほかに、サンプルデータを扱うのにpandasやnumpy、可視化にはMatplotlibについても学んでおくことで、スムーズに解析を行うことができます。
また、クラスタリングは多変量解析の1種でもあるため、統計学の基本についても学んでおくといいですね。

『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
まとめ
データサイエンスではクラスタリングを扱えることが重要となります。
特に市場調査や新商品をどういったターゲット層に届けるかなどのマーケティングに絶大な効果を発揮します。
pythonのライブラリを使えば、少ない工程でクラスタリングを行うことができます。
ぜひクラスタリングをマーケティングに活用してみてください。





