MLP(多層パーセプトロン)という言葉を聞いたことはありますか?
そのそもMLPってなに?
なんとなくイメージはわかっているけど、どこに注目すればいいの?
という方向けに、MLPについて解説していきます。

本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
パーセプトロンとは
まずはパーセプトロンについて確認していきましょう。
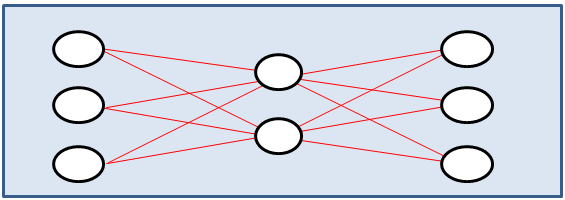
このようなニューラルネットワークを示した図を見たことがある人も多いと思います。
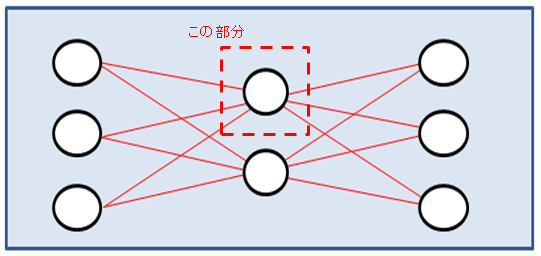
今回確認するパーセプトロンは上の図の点線で囲まれた部分です。もともと人間の脳にあるニューロンを模して造られており、このパーセプトロンに入ってくる入力の値に「重みをかけ、バイアスを足し、活性化関数をかける」動作を行います。
具体的な特徴についてはこの後細かく確認していきます。
ニューラルネットワークとは違うの?
この図を見ると、ニューラルネットワークと何が違うの?という疑問が出てくると思います。一度まとめておきましょう。
パーセプトロン
上の項で示したニューラルネットワークを構成する一つの丸の部分を指します。具体的な働きなどはこの後順に説明していきます。
ニューロン
パーセプトロンと非常に似た働きをします。
- パーセプトロン:入力が数値
- ニューロン:入力が電気
というのが大きな違いです。もともとパーセプトロンは人間の脳のニューロン部分を模して作成されています。
ニューラルネットワーク
上記のパーセプトロンを使用して人間の脳を模して造られたモデルです。これを重ねることにより、複雑な問題に対しても高精度なモデルを作成することが可能になりました。
以下の記事では機械学習とディープラーニングの違いを解説しています。

どのように使われているの?
では、ここからはもう少し詳しくパーセプトロンを見ていきましょう。まずは具体的にどのような働きをしており、どのような計算をしているかを確認します。
具体的な動作
ここまでで、パーセプトロンはニューラルネットワークの図の中で、丸で示されている部分であることを確認しました。また、パーセプトロンは数値を入力して数値を出力することも確認してきました。では、具体的にどのように動作しているのでしょう。
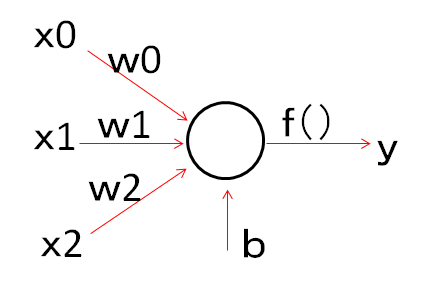
上の図に従って順番に説明していきます。なお、図中の表示に関して何を示しているかを簡単に示しておきます。こちらもあとから説明します。
- x:入力
- w:重み
- b:バイアス
- f():活性化関数
- y:出力
重み
ニューラルネットワークの図からもわかるように、パーセプトロンにはいくつかの入力からデータが入ってきます。まずはそれに、各重みをかけます。図の[w0、w1、w2]の部分です。入ってきたデータに重みをかけるところを式で示すと、
x0・w0+x1・w1+x2・w2
式でかくとわかりにくいですが、何かを予測する際にそれぞれの入力の重要さを見ているということですね。図で考えると、答えを出力するにあたってx0の値が重要であればw0の値が大きくなってきますし、逆に出力にあまり関係がないのであればw0が小さくなっていきます。
バイアス
その後、先ほどの式にバイアス「b」を足します。式で表すと以下のようになります。
x0・w0+x1・w1+x2・w2+b
活性化関数
最終的にパーセプトロンからyとして出力するときには、先ほどの式を活性化関数に当てはめて出力します。式で表すと以下のようになります。
f(x0・w0+x1・w1+x2・w2+b)
活性化関数を通す前の式はただの一次関数なので、結局一次関数で分離をする問題しか対応できず、モデルの表現度が高くなりません。このことをよく、線形分離できないので、表現力が低い、と言ったりします。この活性化関数の導入でモデルが非線形の分離問題に対応でき、表現力が増加して最近の高精度な画像認識ができるようになっています。
この活性化関数ですが、目的に応じていろいろなものを選択しますが、ここでは代表的なものをいくつか紹介したいと思います。
シグモイド(sigmoid)
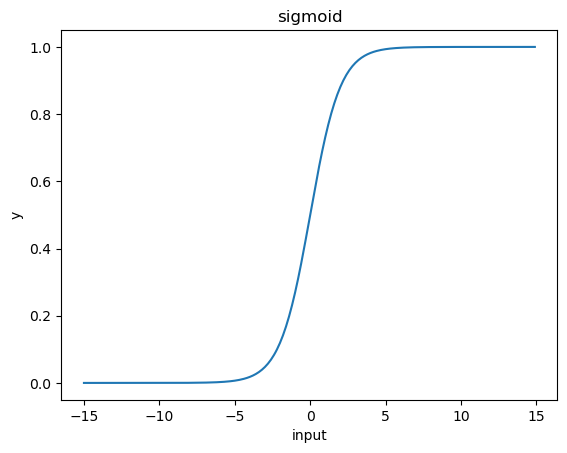
シグモイド関数は上記のようなグラフになります。横軸が入力、縦軸が出力です。y=f(input)という見方をしてください。
グラフを見てわかるように変換前の数値が大きすぎても小さすぎても出力の値は0から1の間になります。
また、sigmoid関数は傾きが小さく、微分値の最大値が0.25にしかならないため、層を重ねることにより勾配消失問題が発生しやすいという問題があります。そのことが当初層を深くすることの妨げとなっていました。
tanh
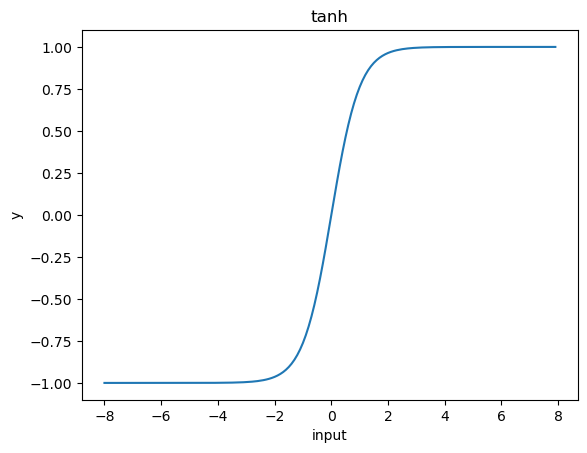
tanhもsigmoidと似た形をとっており、にた特徴を示します。
ReLu
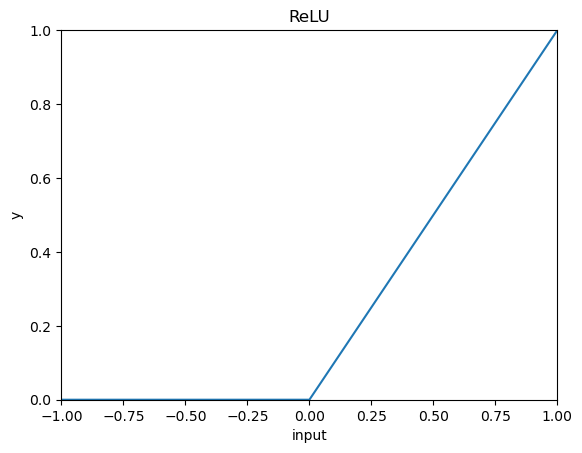
ReLu関数(Rectified Linear Unit)は上のような関数になります。グラフを見ていただくとわかるように、入力が0以上では入力と同じ値を返します。そのため勾配消失問題に強く、比較的よく使用される活性化関数であると思います。
Leaky ReLu
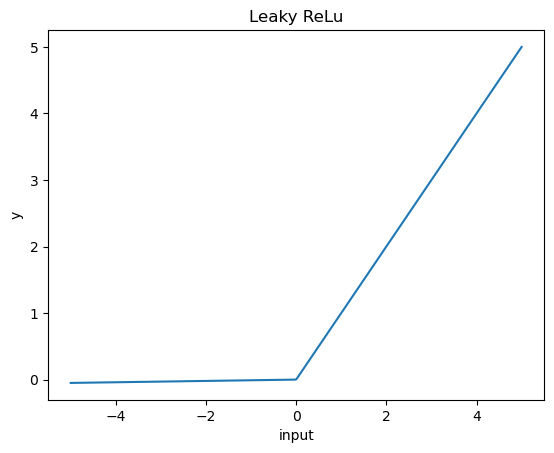
先ほどのReLuはかなり優秀な活性化関数でしたが、マイナス部分をすべて切り落としてしまうため、マイナス側に数値が固まった場合はきれいにデータを表現できないという問題がありました。そのため、マイナス側とプラス側の傾きを変え、マイナス側も採用することにより、さらに良いモデルを作成することができます。
なお、それならy=input・xの式に当てはめればよいのでは?という疑問が出てきますが、最初に説明した通り活性化関数を使用する目的は出力の非線形化なので、このような関数が考えられています。
softmax
softmax関数は少し特殊な関数です。このsoftmax関数は設定した関数の出力の合計が1になるように値を出力します。
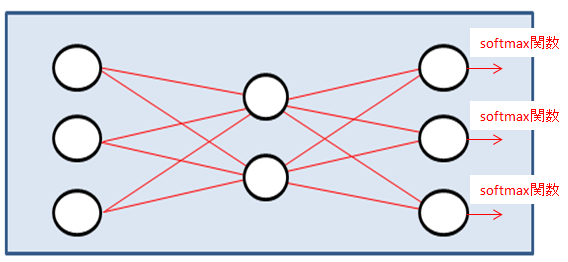
たとえば上の図で、出力部分にsoftmax関数を設定しています。この場合、この3つのパーセプトロンの出力の合計が1になるような出力となります。多クラス分類をする際に出力層に設定し、入力がどの分類になるかを予測する場合などに使用します。
上の図の場合では、上のクラスの確率0.97、中のクラスの確率0.02、下のクラスの確率0.01のような形で計1として出力されます。
MLP(多層パーセプトロン)とは
やっとここでタイトルにあるMLP(Multi Layer Perceptron:多層パーセプトロン)が出てきます。MLPはその名の通り、既出のパーセプトロンを多層に重ねたものになります。
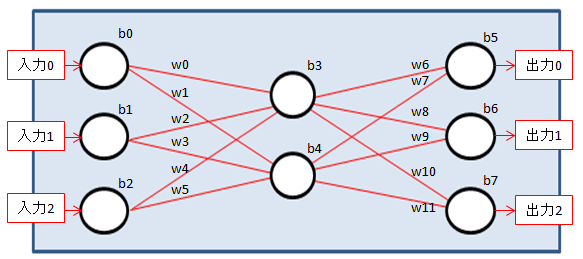
冒頭で出てきたニューラルネットワークの図に、今回見てきたデータの流れを書き入れてみました。各パーセプトロンに重みとバイアスを学習させており、層が増えれば増えるほど、パーセプトロンが増えれば増えるほど学習する内容が爆発的に増えていくのがわかるかとおもいます。
しかし、画像認識などパーセプトロンの層を多層に重ねることによりモデルの表現力があがり、それによって学習する変数の量もそれによる計算量も増加しています。
ディープラーニングに関しては以下の記事でも解説しているので、合わせて参照してみてください。

『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
まとめ
今回は機械学習のMLP(多層パーセプトロン)と、その計算方法についてみてきました。パーセプトロンの働きの部分、「重みをかけてバイアスを足して活性化関数をかける」動作の部分が理解できるとニューラルネットワークの理解につながりますので、ぜひ今回の内容を役立ててください。