この記事では、ハイパーパラメータについて紹介します。
ハイパーパラメータは、機械学習モデルの性能や動作に影響を与える要素です。
記事の中では、ハイパーパラメータの役割や選び方について分かりやすく説明しています。 また、具体的なハイパーパラメータの種類や調整方法、過学習や欠損値の影響についても触れていきます。 読者がハイパーパラメータの理解と選び方をスムーズに習得できるよう、シンプルな表現と実例、図などを用いてわかりやすく解説します。
- ハイパーパラメータの役割や選び方
- ハイパーパラメータの種類や調整方法
- 過学習や欠損値の影響
ハイパーパラメータの重要性と選び方を把握することで、読者の皆様が機械学習プロジェクトでより良い結果を得る一助となることを願っています。

本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
ハイパーパラメータとは?
ハイパーパラメータは、機械学習モデルの振る舞いを制御する設定や調整可能なパラメータのことを指します。
これは、モデル自体が学習データから学習する学習パラメータとは異なり、人間が手動で設定する必要があります。ハイパーパラメータの選択は、モデルの性能や学習の速さに大きな影響を与えます。 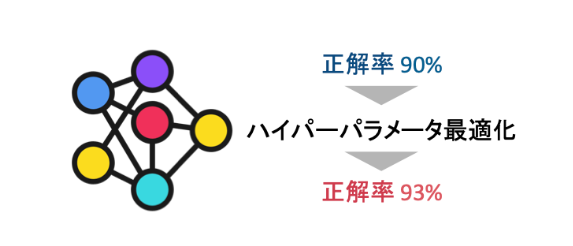 具体的な例を挙げてみましょう。
具体的な例を挙げてみましょう。
あなたが自動運転車を開発しており、車のスピードを制御するアルゴリズムを構築するとします。このアルゴリズムのハイパーパラメータには、最適な速度を決定するための距離の閾値や急ブレーキを行う際の速度減少の度合いなどが含まれます。
重要なのは、これらのハイパーパラメータの値を適切に設定することです。例えば、閾値を低く設定すると、車は障害物に近づく前に減速するため、安全性は高まりますが、運転時間が長くなるかもしれません。逆に、閾値を高く設定すると、車は障害物に近づいてから急ブレーキをかけるため、安全性は低下しますが、効率的な運転が可能です。
ハイパーパラメータの選択は、試行錯誤とドメイン知識に基づいて行われます。ハイパーパラメータチューニングと呼ばれるプロセスでは、異なる値を試してモデルの性能を評価し、最適な組み合わせを見つけることを目指します。
総括すると、ハイパーパラメータは、機械学習モデルの設定や制御を行うパラメータであり、モデルの性能や振る舞いに大きな影響を与える重要な要素です。これらの値を適切に調整することで、モデルの良好な性能を引き出すことができます。
代表的なハイパーパラメータ
学習率 / Learning Rate
学習率は、モデルが学習データからパラメータを更新する際のステップの大きさを制御します。高い学習率は急速な学習をもたらす一方、収束しない可能性があります。低い学習率は安定した収束をもたらす一方、学習に時間がかかることがあります。
バッチサイズ / Batch Size
バッチサイズは、一度にモデルが見るサンプルの数を指します。大きなバッチサイズは学習の安定性を高めますが、メモリや計算リソースの制約があるかもしれません。小さなバッチサイズはよりランダムな更新を行うため、ノイズの影響を受けにくいですが、収束に時間がかかることがあります。
過学習とは、機械学習において、学習データに過剰に適合してしまい、未知のデータに対しては適合できない状態を指します。 過学習が発生すると、学習データに対しては高い精度で予測することができますが、未知のデータに対しては精度が低下してしまいます。
エポック数 / Number of Epochs
エポック数は、学習データ全体を何回反復して学習させるかを指します。十分なエポック数を設定しないと、モデルが十分に学習しない可能性があります。しかし、過剰なエポック数は過学習を引き起こす恐れがあります。
隠れ層のユニット数 / Number of Units in Hidden Layers
ニューラルネットワークの隠れ層に含まれるユニット / ニューロンの数です。多くのユニットを持つ隠れ層は複雑なモデルを表現できますが、過学習のリスクがあります。適切な数を選ぶことが重要です。
正則化パラメータ / Regularization Parameter
正則化は過学習を防ぐための手法で、正則化パラメータはその強度を制御します。正則化パラメータが大きいほど、モデルはよりシンプルな形に近づきますが、性能が低下する可能性があります。
ハイパーパラメータの重要性
具体例として、画像分類のタスクを考えてみましょう。あるデータセットには犬と猫の画像が含まれており、これらを分類するためのニューラルネットワークモデルを構築することを考えます。
学習率の重要性
学習率はモデルの収束速度に大きな影響を与えます。高すぎる学習率を選ぶと、モデルの更新が大きすぎて発散しやすくなります。一方で、低すぎる学習率では学習が遅くなります。例えば、学習率を十分に調整しない場合、モデルは収束せず、正しい予測が得られない可能性があります。
バッチサイズの重要性
バッチサイズはミニバッチごとに行うパラメータ更新の回数を決定します。大きなバッチサイズを選ぶと、計算効率は向上しますが、モデルが局所的な最適解に早く収束する可能性があります。逆に、小さなバッチサイズでは学習がランダムになり、より多くの反復が必要です。バッチサイズの選択が悪い場合、学習が不安定になり、モデルの性能が低下することがあります。
エポック数の重要性
エポック数は学習データ全体を何回も繰り返し学習させる回数を指します。十分なエポック数を設定しないと、モデルはデータのパターンを学びきれず、未知のデータに対する予測性能が低下します。
しかし、過剰なエポック数を設定すると、過学習が起こり、訓練データに過度に適合したモデルになる可能性があります。訓練データに過度に適合すると、新しいデータへの応用が効かなくなってしまいます。
これらの具体例からわかるように、ハイパーパラメータの選択はモデルの性能に大きな影響を与えます。適切なハイパーパラメータの選択によって、モデルの学習が安定し、高い性能を発揮することができます。ハイパーパラメータの効果を実際に試してみながら、最適な設定を見つける練習を行うことが重要です。
ハイパーパラメータの調整方法
グリッドサーチ / Grid Search
グリッドサーチは、あらかじめ指定した範囲内から複数のハイパーパラメータの組み合わせを試す方法です。
具体的な手順を見てみましょう。例えば、ニューラルネットワークの学習率と隠れ層(中間層)のユニット数のハイパーパラメータを調整する場合を考えます。
・学習率:[0.01, 0.001, 0.0001]
・隠れ層のユニット数:[64, 128, 256]
これらの値を組み合わせて全ての組み合わせを試し、最も良い性能を示す組み合わせを選びます。グリッドサーチは簡単で確実な方法ですが、組み合わせが多い場合に計算負荷が高くなることがあります。 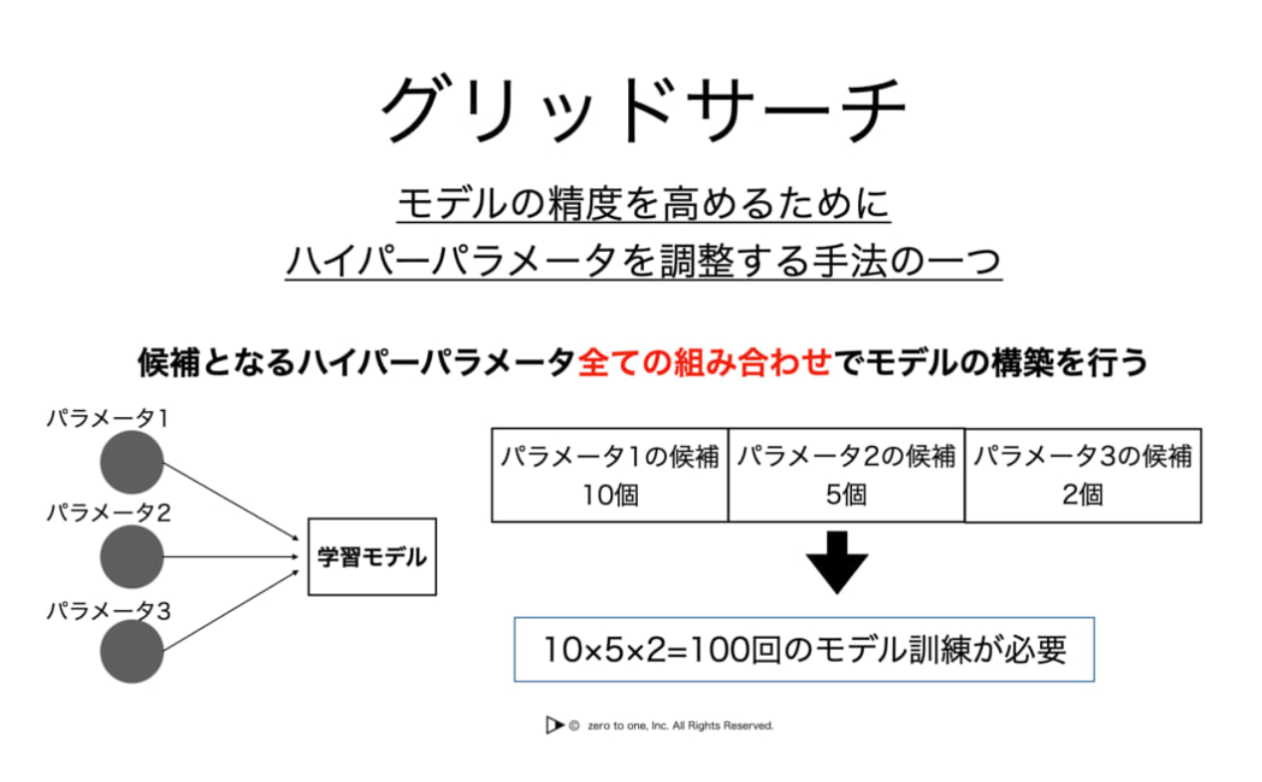
ランダムサーチ / Random Search
ランダムサーチは、指定された範囲からランダムにハイパーパラメータの組み合わせを選ぶ方法です。これにより、広い範囲を効率的に探索することができます。
例えば、前述の学習率と隠れ層(中間層)のユニット数のハイパーパラメータをランダムサーチで調整する場合を考えます。
・学習率:ランダムに[0.0001, 0.01]の間で選ぶ
・隠れ層のユニット数:ランダムに[64, 256]の間で選ぶ
ランダムサーチは、効率的に良いハイパーパラメータの値を見つけるために、試行錯誤を繰り返すことができます。 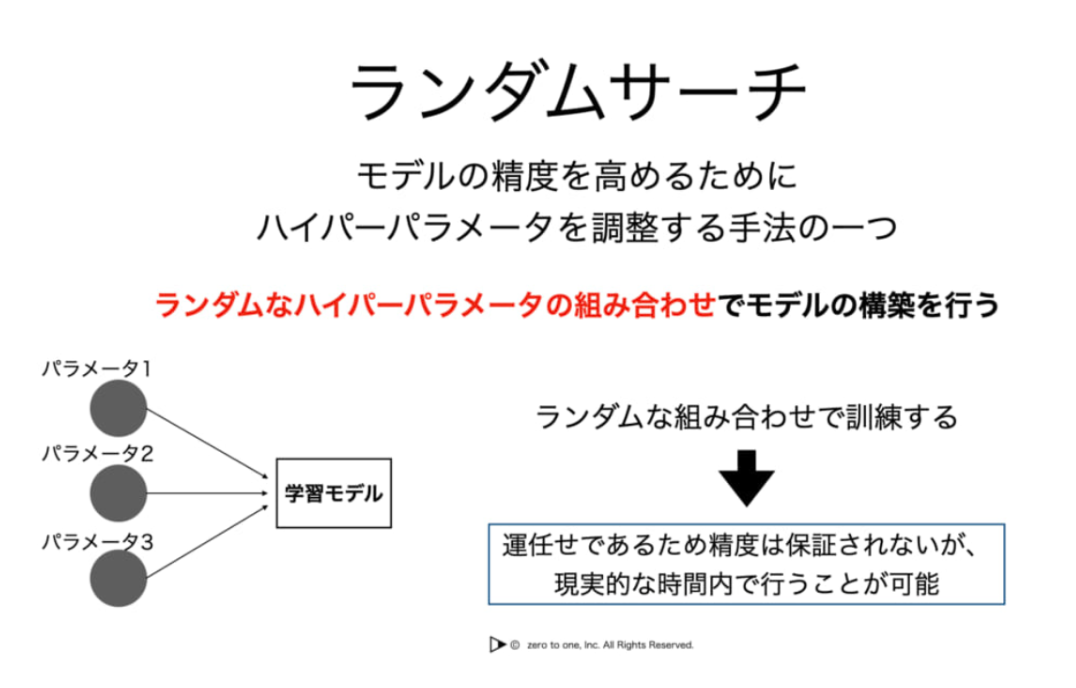
ベイズ最適化 / Bayesian Optimization
ベイズ最適化は、過去の試行結果を元に、次に試すべきハイパーパラメータの組み合わせを選ぶ方法です。このアプローチは効率的であり、少ない試行回数で良い結果を得ることができます。 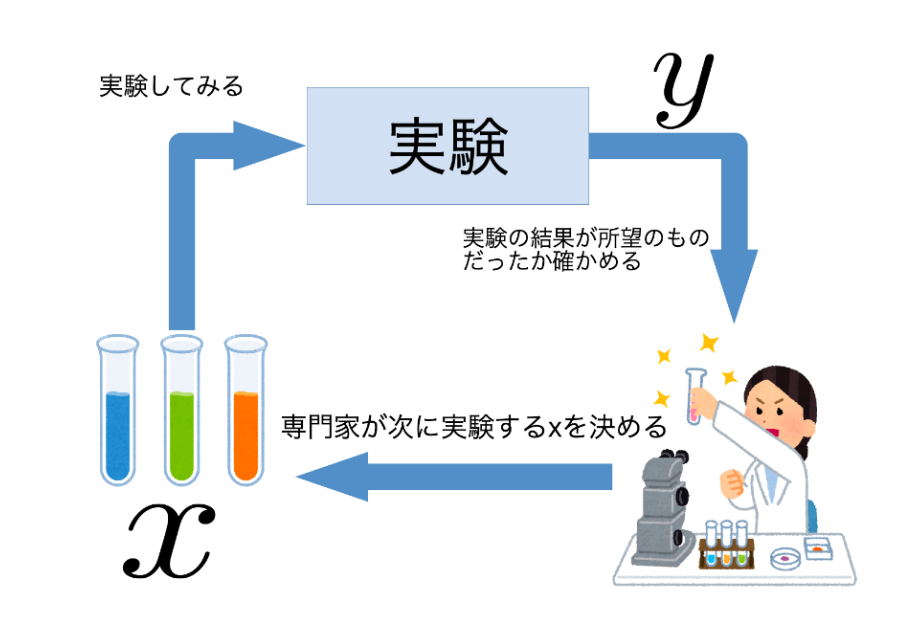 これらの調整方法を使って、適切なハイパーパラメータを見つけることが重要です。初学者の場合、ランダムサーチやベイズ最適化のような方法を始めるのがおすすめです。試行錯誤を通じて、モデルの性能を向上させる方法を学んでいくことが大切です。
これらの調整方法を使って、適切なハイパーパラメータを見つけることが重要です。初学者の場合、ランダムサーチやベイズ最適化のような方法を始めるのがおすすめです。試行錯誤を通じて、モデルの性能を向上させる方法を学んでいくことが大切です。
ベイズ最適化について以下の記事でより詳しく解説しています!

具体例によるハイパーパラメータ調整
今回は、手書き数字の画像を分類するためのニューラルネットワークを考えます。このニューラルネットワークのハイパーパラメータ調整を行ってみましょう。
タスクの設定
手書き数字の画像分類を行うためのデータセット(例:MNIST)を用意します。このデータセットには0から9までの数字の画像が含まれており、それぞれの画像は28×28ピクセルのサイズです。
モデルの構築
ニューラルネットワークのモデルを定義します。例として、2つの隠れ層(中間層)を持つモデルを考えます。隠れ層(中間層)とは、ニューラルネットワークの入力層と出力層の間に存在する層です。入力層から受け取ったデータを処理し、出力層に渡す役割を担います。
ハイパーパラメータの選択
ハイパーパラメータとして、学習率と隠れ層(中間層)のユニット数を調整することにします。
ハイパーパラメータ調整のステップ
学習率の初期値を0.001、隠れ層(中間層)のユニット数の初期値を128とします。
上記の初期値を使用してモデルを学習させます。訓練データを使ってエポック数などのハイパーパラメータも設定し、モデルを学習させます。
モデルをテストデータで評価し、性能指標(例:正解率)を記録します。
現在の性能を元に、ハイパーパラメータを変更して次の試行を行います。例えば、学習率を0.01に、隠れ層(中間層)のユニット数を64に変更して再度学習を行います。
新しいハイパーパラメータでモデルを評価し、性能を前の試行と比較します。性能が向上した場合、新しいハイパーパラメータを採用します。そうでなければ、再びハイパーパラメータを変更して試行を繰り返します。
このプロセスを繰り返すことで、より良いハイパーパラメータの組み合わせを見つけることができます。初めはランダムな試行から始めて、性能向上の傾向を見つけることが大切です。
ハイパーパラメータ最適化のツール
ハイパーパラメータ最適化を手動で行うのは煩雑で時間がかかることがあります。そこで、自動的にハイパーパラメータの組み合わせを試して性能を最大化するツールが開発されています。
GridSearchCV
Scikit-learnライブラリに含まれるツールで、グリッドサーチを行います。あらかじめ指定したハイパーパラメータの組み合わせを試し、最適な組み合わせを見つける手法です。
RandomizedSearchCV
同様にScikit-learnに含まれるツールで、ランダムサーチを行います。指定した範囲内からランダムにハイパーパラメータを選んで試し、最適な組み合わせを見つけます。
Bayesian Optimization Libraries
ベイズ最適化を行うための専用ライブラリもあります。例えば、HyperoptやOptunaなどがあります。これらのライブラリは、過去の試行結果に基づいて次に試すべきハイパーパラメータを選びます。
ハイパーパラメータ最適化の自動化
自動化の手法を使ってハイパーパラメータの最適化を行うには、以下の手順を追うことが一般的です。
目的関数の定義
最適化したい性能指標(例:正解率)を最大化する目的関数を定義します。この関数はハイパーパラメータを受け取り、モデルを学習させて評価指標を返すものです。
最適化の実行
選んだ最適化ツールを使用して、定義した目的関数を最大化するハイパーパラメータを探索します。ツールは自動的に組み合わせを試し、最適なハイパーパラメータを見つけます。
結果の分析
最適化の結果を分析して、最も性能が良いハイパーパラメータの組み合わせを特定します。性能が改善されているか、どのハイパーパラメータが重要だったかなどを考察します。
自動化ツールを使うことで、手動で試行錯誤する手間を省きながら、効率的にハイパーパラメータの最適化を行うことができます。初学者の方は、Scikit-learnのGridSearchCVやRandomizedSearchCVから始めるのがおすすめです。

『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
まとめ
ハイパーパラメータは機械学習モデルの性能や収束速度に大きな影響を与える要素であり、適切なハイパーパラメータ設定は、モデルの優れた性能を引き出す鍵です。
自動化ツールを活用して最適なハイパーパラメータを探索することは効率的で、試行錯誤の手間を軽減します。
初学者でもハイパーパラメータの重要性を理解し、最適化手法を用いてモデルのパフォーマンスを向上させることが可能です。