ニューラルネットワークはいろいろなことができそうなのでぜひとも挑戦してみたいけど
なにをすればいいの?
とても難しそう
という方も多いと思います。今回はTensorflowと、簡単に高品質なニューラルネットワークを作成できるkerasをつかって、実際にモデルを作成しながらこれらのライブラリについて解説していきます。

本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
ニューラルネットワークとは
ニューラルネットワークは、人間の脳が情報を処理する仕組みを模倣したコンピュータの学習モデルです。人間の脳にあるニューロン(神経細胞)を模したパーセプトロンが多数連携して動作します。
このニューラルネットワークを作成できるライブラリに今回紹介するTensorflowやkerasがあります。このライブラリを使用することによりニューラルネットワークのモデルを作成することが可能です。
なお、Tensorflowやkeras以外にもPyTorch、caffeなどのライブラリがあります。
ニューラルネットワークに関しては、以下の記事でも紹介しているので参考にしてください。

Tensorflowとkeras
Tensorflowとは
TensorFlowは、Googleが開発したオープンソースの機械学習ライブラリです。CPUとGPUの両方で動作し、分散コンピューティングをサポートしているなど非常にスケーラブルなことで知られています。
kerasとは
Kerasは、もともとTheanoをベースに、現在はTensorflowをベースにPythonで書かれたオープンソースのニューラルネットワークライブラリで、迅速な実験を可能にすることを目指して設計されました。kerasのおかげでシンプルで使いやすいインターフェースのままTensorflowの機能を活用することが可能になっています。
kerasで実装してみる
kerasを使用するとニューラルネットワークを簡単に作成することが可能です。今回はkerasから使用できるデータセット、fashion-mnistを使用して衣料品の画像判別をしてみたいと思います。
fashion-mnistとは
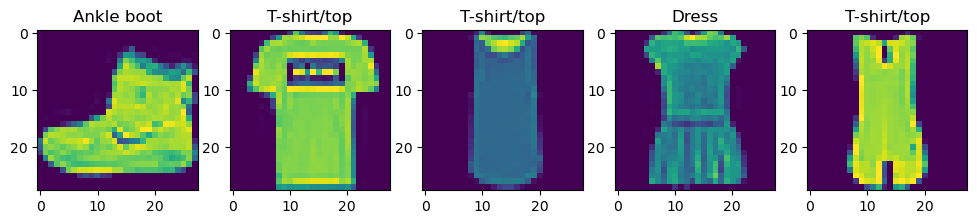
fashion-mnistは上記のよう衣料品の画像のデータセットです。28x28のデータサイズで10種類のカテゴリーで作成されており、kerasの学習には最適なデータセットです。
インポート
import matplotlib.pyplot as plt
import tensorflow as tf
from sklearn.model_selection import train_test_split
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Flatten, Dense, Dropout, Conv2D, MaxPooling2Dまずはライブラリをインポートします。
- import matplotlib.pyplot as plt:映像を表示するためのライブラリ、「matplotlib」をインポートします。
- import tensorflow as tf:Tensorflowのインポートをします。一般的に「tf」という名前でインポートします。
- from sklearn.model_selection import train_test_split:データを学習データと検証データに分けるときに使用します。
- from tensorflow.keras import Sequential:今回の作成方法、Sequentialでモデルを作成するために使用します。
- from tensorflow.keras.layers import Flatten, Dense, Dropout, Conv2D, MaxPooling2D:モデルを作成するために使用する各層の呼び出しに使用します。
Sequentialモデル
kerasでのモデル作成方法は3種類あります。
- Sequentialモデル:今回作成する方法です。ニューラルモデルの概要が理解できていると、感覚的にモデルを積み上げるイメージで作成できます。
- Functional API:Sequentialモデルにくらべ、自由度のある記述をすることができます。その分書き方は少しレベルが上がります。
- サブクラス化:完全に1からモデルを作成します。非常に自由度のある方法ですが、モデルの作成をすべて手動で行う必要があります。
今回はこの中にあるSequentialモデルで作成します。高度なモデルを比較的簡単に作成することができるため、kerasを使用する大きなメリットとなります。
ライブラリのインポートについて
ライブラリのインポートに関して、今回例えば「Dense」に関しては、一番最後の行で「from tensorflow.keras.layers import Dense」で呼び出しています。こうすると使用する際に「Dense」でそのまま使用できますが、呼び出し状態を見てわかるように「Flatten、Dropout、Conv2D、MaxPooling2D」とすべて呼び出す必要があります。
逆に呼び出し時に個別に呼び出さず、使用時に「tf.keras.layers.Dense」として使用することも可能です。今回はモデル作成時に複雑にならないように先に呼び出していますが、tfから呼び出すもの、kerasまで呼び出しておくもの、layersまで呼び出すものなどいろいろなサイトが存在するので、好きなものを使用してください。
データの準備
(x, y), (test_x, test_y) = tf.keras.datasets.fashion_mnist.load_data()
train_x, val_x, train_y, val_y = train_test_split(x, y, train_size=0.8)
target_name = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']fashion_mnistのデータは「tf.keras.datasets.fashion_mnist.load_data()」で呼び出すことが可能です。その後、xとyを「train_test_split()」で8割のトレーニングデータと2割の検証データに分けています。
また、fashion_mnistはターゲットの名前がないため、これは手動でリストに格納しています。
データの確認
plt.figure(figsize=(12,5))
for i,j in enumerate(range(1, 6)):
plt.subplot(1, 5, j)
plt.title(target_name[y[i]])
plt.imshow(x[i])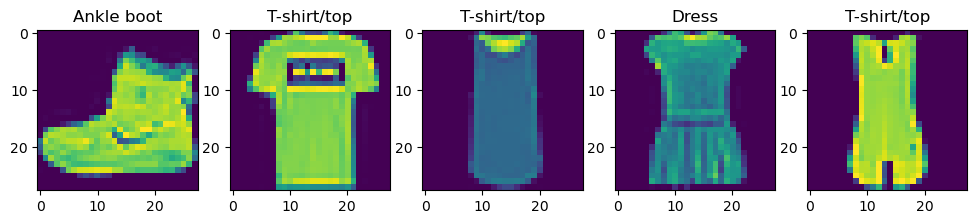
データの中身を確認してみます。最初の5データを並べてみました。まとめて書くとわかりにくい!という方は下のコードと同じ内容なので、参考にしてみてください。
plt.figure(figsize=(12,5))
plt.subplot(1, 5, 1)
plt.title(target_name[y[0]])
plt.imshow(x[0])
plt.subplot(1, 5, 2)
plt.title(target_name[y[1]])
plt.imshow(x[1])
plt.subplot(1, 5, 3)
plt.title(target_name[y[2]])
plt.imshow(x[2])
plt.subplot(1, 5, 4)
plt.title(target_name[y[3]])
plt.imshow(x[3])
plt.subplot(1, 5, 5)
plt.title(target_name[y[4]])
plt.imshow(x[4])モデルを作成する
input_shape = (train_x.shape[1], train_x.shape[2], 1)
model = Sequential(name='test_model')
model.add(Flatten(name='Flatten', input_shape=input_shape))
model.add(Dense(128, activation='relu', name='Dense'))
model.add(Dropout(0.2, name='Dropout'))
model.add(Dense(10, activation='softmax', name='Output'))
model.summary()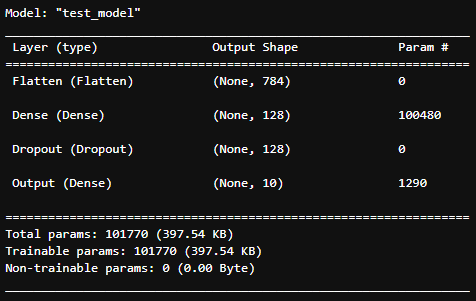
基本的なモデル作成の流れは、
- model = Sequential()でモデルを作成
- model.add()でモデルを積み上げる
- 最後にmodel.summary()でモデルの形を確認
となります。コード中の「name=」は省略可能なので、最初はさらに簡単なコードにすることが可能です。
model=Sequential()
「model=Sequential()」でモデルを作成します。
今回はコードをすべて1ブロック内に記入していますが、最初に書くときは入力ミスやデータの次元の問題などで、とにかくエラーが出ると思います。そのため以下のように1ブロックずつわけて記入し、モデルが完成してから1ブロックにコピーするとスムーズだと思います。このような書き方ができるのもSequentialモデルの良いところです。
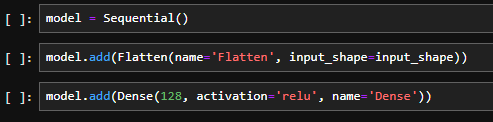
なお、モデルにリスト形式でモデルを与える方法もあるので、CNNを使ったモデルを以下に示しておきます。CNNに関しては以下の記事を参照してください。

model_1 = Sequential([
Conv2D(16, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu', input_shape=input_shape, name='Conv'),
MaxPooling2D((2, 2), strides=(1, 1), name='Pooling'),
Flatten(name='Flatten'),
Dense(128, activation='relu', name='Dense'),
Dropout(0.2, name='Dropout'),
Dense(10, activation='softmax', name='Output'),
], name='test_model_2')
model_1.summary()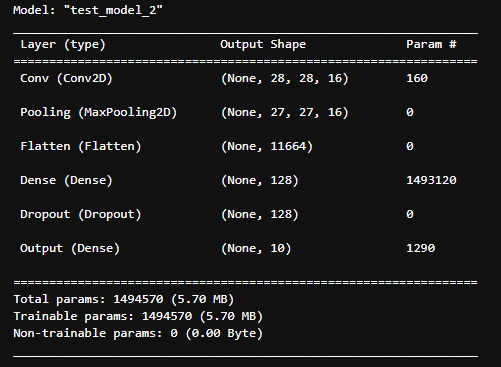
Flatten
「Flatten」は入力データを1次元に並べます。入力データはデータ確認のところでもあるように28x28のデータですが、ニューラルネットワークでは1次元のデータを解析します。そのため、入力データを1列のデータに変換するのがFlattenです。
なお、Flattenに限ったことではないのですが、入力層には「input_shape」を指定しましょう。これをしないとデータの形状がわからないため、のちの「summary()」でモデルの形を参照できません。なお、ここで指定しなくても、のちの「model.compile」をすればsummaryを参照できるようになります。
Dense
「Dense」は全結合層を作成します。全結合層とは、前の層すべてと結合されている層です。層の数と活性化関数を指定します。層の数、活性化関数に関しては以下の記事を参照していただけるとよいと思います。今回はreluを使用しています。
Dropout
ドロップアウトを追加します。ドロップアウトは先ほどの全結合層で結合されているすべての接続のうち、特定の割合で接続を切って学習します。これによって、学習用データだけに特化して学習が進む過学習、オーバーフィッティングに効果があります。
モデルの学習
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
history = model.fit(train_x, train_y, epochs=40, validation_data=(val_x, val_y))モデルをcompileして、optimizerとlossを指定し、学習します。
学習時の記録は「history」に記録されていきます。以下のようにhistoryに記録されている情報を呼び出すことにより学習時の記録が確認できます。
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['loss', 'val_loss'], loc='upper left')
plt.show()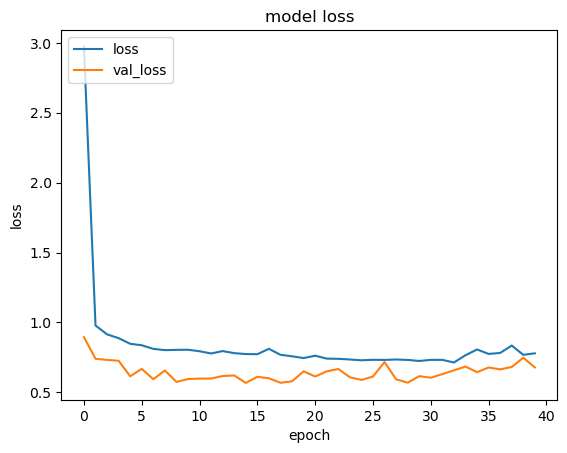
このようにすることで、学習時のlossとval_lossの推移が確認できます。
なお、「loss」と「val_loss」の違いですが、「loss」は学習時のlossの値で、正解と予測の差分です。この値を少なくするように学習を進めます。「val_loss」は検証用データでlossを計算した値です。
先ほども出てきたように、モデルは「loss」の値を少なくするように学習データを使用して学習を進めます。ただし学習データのみを使用して学習するため、学習データのみにあてはまり新たなデータでうまく予測できなくなる、いわゆるオーバーフィッティング状態になることがあります。グラフ上では「loss」が下がっていくのに「val_loss」が上がってしまう状態です。
モデルの学習は、どのようなデータに対してもよい予測精度を保つことが目的なので、このようなオーバーフィッティングを起こしていないかを確認するためにこのように2つのロスを確認します。
なお、先ほど参考で作成したCNNのモデルの結果とlossの値を比較してみましょう。下記のようにCNNで認識率が上がっていることが確認できます。
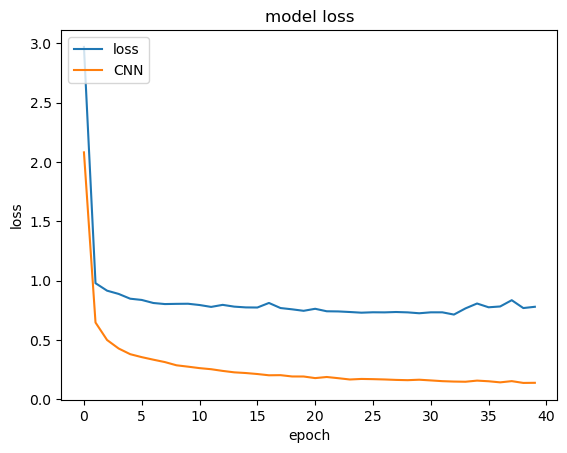

『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
まとめ
今回はkerasの実装をベースにTensorflowとkerasについてみてきました。kerasは比較的簡単なコードで非常に有効なニューラルネットワークを作成することが可能です。ぜひこの内容をきっかけとしてマスターしていただければと思います。