

PythonとMeCabの使い方を習得できれば、さまざまな形態素解析を自動でできるようになります。PythonとMeCabを使って、形態素解析をしようとしている方のなかには、下記のように疑問や悩みがある方も多いのではないでしょうか。
- Taggerクラスの引数がよくわからない
- インストールでつまづいていて先に進めない…
今回は、PythonでMeCabの分かち書きから名詞を取り出す実装手順をプログラミング初心者向けにわかりやすく解説します。
また、MeCabのTaggerクラスの使い方やMeCab・辞書のインストール方法の解説を通じて、実装に必要な知識もインプットできます。
PythonのMeCabをマスターしたい方は、ぜひ最後までご覧ください。

本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
【予備知識】MeCabのTaggerクラスとは?
MeCabを使いこなせるようにするうえで重要なのが「Taggerクラス」の理解です。
MeCabのTaggerクラスでは、形態素解析の出力方法や、辞書の種類を引数で指定できる
Taggerクラスでは、全部で25種類の引数を指定できます。なかでも、よく使われる引数は下記のとおりです。
- -O:出力方法の指定
- -r・-u:辞書指定
MeCabでは分かち書きだけではなく、読み方の情報だけを取り出すなど、出力方法を選べます。
また、研究機関や有志が作った「システム辞書」以外にも、「ユーザー辞書」と呼ばれる個人用のオリジナル辞書の使用も可能です。それぞれの辞書を使う際には、異なる引数を渡します。
また、Taggerクラスには「parse・parseToNode」と呼ばれるメソッドがあります。それぞれのメソッドを呼び出すことで、形態素解析の結果表示・取得が可能です。
MeCabで形態素解析を行うためには、まずTaggerクラスの使い方を習得する必要があります。では、これからTaggerクラスでできる3つのことを具体的に解説します。
- 出力方法の指定
- 辞書の指定
- 形態素の情報取得
どれもMeCabの基本的なことなので、チェックしておきましょう!
出力方法の指定
Taggerクラスの引数のうち「-O」を設定することで、形態素解析の結果の出力方法を指定できます。具体的な「-O」引数の渡し方は、下記のとおりです。
MeCab.Tagger("-Ochasen")
「-O」のなかにもいくつか種類があって、ニーズに合わせて使い分けることができます。下記の表にて、Taggerクラスの「-O」引数の種類別に出力方式をまとめたので、チェックしておきましょう。
| 引数 | 出力方式 | 出力画像 |
|---|---|---|
| -Owakati | 分かち書きの結果を出力 |  |
| -Ochasen | Chasenの出力フォーマットで表示 | 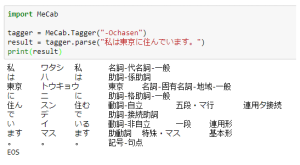 |
| -Oyomi | 読み方を出力 | 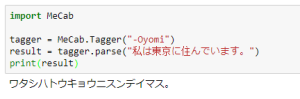 |
| -Odump | 全情報を出力 |  7 これ 名詞,代名詞,一般,*,*,*, これ,コレ,コレ 0 6 1306 1306 59 6 0 1 0.000000 0.000000 0.000000 2561 15 は 助詞,係助詞,*,*,*,*, は,ハ,ワ 6 9 261 261 16 6 0 1 0.000000 0.000000 0.000000 2987 19 ペン 名詞,一般,*,*,*,*, ペン,ペン,ペン 15 1285 1285 38 7 0 1 0.000000 0.000000 0.000000 8018 49 です 助動詞,*,*,*,特殊・デス,基本形,です,デス,デス 15 21 460 460 25 6 0 1 0.000000 0.000000 0.000000 9331 |
引用:日本テレビ東京で学ぶMeCabのコスト計算/mwSoft
「-O」引数では、全部で4種類の出力方式を指定できます。例えば、全情報を表示する「-Odump」では、品詞や活用形など合わせて10種類の情報を一気に取得可能です。
- 表層形:活用や表記揺れを考慮した、文章中で使用される単語形式
- 品詞:単語を文法上の形態や役割などから、「動詞・名詞・形容詞・形容動詞・副詞・連体詞・接続詞・感動詞・助動詞・助詞」へ分類したもの
- 品詞細分類1~3:辞書の品詞体系に基づいて品詞の属性をさらに分類したもの(名詞の場合には、固有名詞・人名・一般・組織・地域など)
- 活用型:単語の活用の仕方を分類したもの(動詞の場合は「五段活用・上一段活用・下一段活用・カ行変格活用・サ行変格活用」)
- 活用形:活用している動詞・形容詞・形容動詞・助動詞を「未然形・連用形・終止形・連体形・仮定形・命令形」へ分類したもの
- 原形:活用前の形式
- 読み方:単語のフリガナ(学習→ガクシュウ)
- 発音:日本語で発音する方法(学習→ガクシュー)
また「-Ochasen」は、形態素解析エンジンである「ChaSen」の出力フォーマットで出力できる引数です。具体的には下記の情報を得られます。
- 表層形
- 読み方
- 基本形
- 素性(品詞・活用型・活用形)
発音の情報が欲しい場合には「-Odump」を使って、Chasen形式のシンプルな情報がほしい場合には「-OChaSen」を選択するといったように、解析のニーズに合わせて選べるメリットがあります。
辞書の指定
MeCabでは2種類の辞書を指定できます。それぞれをTaggerクラスで指定する方法は、下記のとおりです。
MeCab.Tagger("-d /システム辞書のpath")
MeCab.Tagger("-u /ユーザー辞書のpath")
-dと-uどちらの引数も指定しない場合は、デフォルトのシステム辞書である「IPA辞書」が使用されます。
形態素の情報取得
Taggerクラスの「parse・parseToNode」を呼び出すことで、形態素の情報を取得可能です。parseToNodeの方が詳細な情報を得られるため、よく使用されます。
parseToNodeでは、メソッドの「surface」と「feature」を呼び出すことで、それぞれ下記の情報を取り出せます。
- surface:表層形
- feature:品詞・品詞細分類1・品詞細分類2・品詞細分類3・活用形・活用型・原形・読み方・発音
featureは要素同士が「 , 」で区切られているので、Pythonの「split関数」で分割して必要な情報だけを取り出せます。本記事内の【実装】にて、surfaceとfeatureの使い方を紹介しているので、チェックしておきましょう。
なお、split関数の使い方は下記で詳しく解説しているので、参考にしてみてくださいね!

parseToNodeは、特定の品詞の単語だけを取り出したり、品詞ごとの使用回数をカウントしたりする場合に役立ちます。
【事前準備】MeCabと辞書のインストール手順
実装に進む前に、MeCabを動かすための環境構築方法を解説します。今回は、Anacondaでの環境構築方法をまとめました。なお、Anacondaは既にダウンロード済みである前提で進めます。
具体的な実行環境は下記のとおりです。
- OS:Windows
- IDE:Anaconda
- エディタ:Jupyter Notebook
では、MeCabと辞書のインストール手順を見ていきましょう!
MeCabのインストール
MeCabをAnaconda環境で使えるようにするまでの手順は、下記のとおりです。
- 公式GithubにあるMeCabのexeファイルをWindowsへダウンロード
- MeCabのpathを設定する
- Jupyter NotebookにMeCabをインストール
まず、MeCabのexeファイルをダウンロードしましょう。そして、MeCabのセットアップを行います。
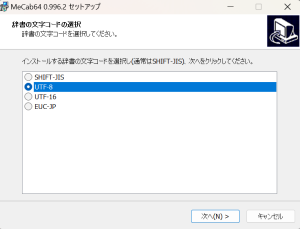
「インストールする辞書の文字コード」を選択するポップアップが表示されたら、必ず「UTF-8」を選んでください。
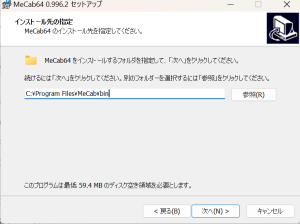
画面に従ってセットアップを進めていくと、インストール先を指定するポップアップが表示されるので、「C:\Program Files\MeCab\bin」と入力しましょう。
pathを通さないと「MeCabがインストールされていない」旨のエラーが発生して、いつまでも実行できないため注意してくださいね!
そして、「MeCabの辞書を作成します」とポップアップが表示されるので「OK」をクリックしてインストールを進めましょう。
最後に、Jupyter Notebook側にMeCabのライブラリである「mecab-python3」をインストールします。notebookの1番上のセルで、下記のコードを入力してください。
!pip install mecab-python3
ライブラリのインストールができると、「Successfully installed mecab-python3」と表示されます。以上で、MeCabのインストールは完了です!本記事で紹介している分かち書きの実装コードを入力して、動くかどうか確かめてみてくださいね。
辞書のインストール
標準辞書以外で必要な場合には、別途辞書をインストールしましょう。辞書はPythonのライブラリで用意されていないため、GitHub上や言語資源開発センターのWebサイト上で一般公開されているものをインストールする必要があります。
今回は、MeCabで使われる頻度が高い「NEologd辞書」をインストールする手順を紹介します。Jupyter Notebookにインストールする際には、下記の1行を入力するだけです。
!pip install neologdn
無事インストールが完了すると、「Successfully installed neologdn-0.5.2」と表示されます。テキストの正規化を行う「normalize」ライブラリを使って、下記のように動作確認をしましょう。
import neologdn
print(neologdn.normalize("ディープラーニング"))
上記を実行して全角カタカナ表記の「ディープラーニング」が出力できれば、問題なく動作できているので、無事インストールが完了したことになります。
【実装】PythonとMeCabで形態素解析を実行
予備知識のインプットと事前準備ができたところで、これからPythonとMeCabを使って日本語文章の形態素解析を実行してみましょう。
今回の具体的なテーマは、PythonとMeCabで分かち書きをした文章から、名詞のみを取り出すコードを実装できるようになることです!
手順は下記のとおりです。
- PythonとMeCabで分かち書きを行う
- 分かち書きをした文章から名詞のみを取り出す
実行環境は事前準備で設定した環境と同じです。では、順番に見ていきましょう。
分かち書きの実装
まずは、MeCabのもっとも基本となる「分かち書き」の実装手順を見ていきましょう。実装コードは下記のとおりです。
# mecabのインポート
import MeCab
# 解析する文章を格納
str = "AI学習の悩みや疑問は、Tech Teacherにお任せ!"
# mecabのTaggerメソッドを呼び出す
tagger = MeCab.Tagger()
# mecabによる形態素解析の結果を表示
print(tagger.parse(str))
コードを実行した結果は下記のとおりです。

MeCabではTaggerクラスのparseメソッドに解析対象の文章を渡すだけで、分かち書きが完了します!
parseメソッドでは、形態素解析の結果をstr型で返します。分かち書きの結果を表示したいときには、parseメソッドが便利です。
【+α】文章の名詞のみを取り出す
次は、TaggerクラスのparseToNodeメソッドを使って、MeCabが名詞と判断した単語のみを取り出すコードを実装してみましょう!
先ほど実装した分かち書きのコードに数行付け足すだけで完了するので、とても簡単です。実装コードは下記のとおりです。
# mecabのインポート
import MeCab
# 解析する文章を格納
str = "AI学習の悩みや疑問は、Tech Teacherにお任せ!"
# mecabのTaggerメソッドを呼び出す
tagger = MeCab.Tagger()
# ==== ここから下のコードが新しいコード ====
# 形態素解析の情報を取得
nodes = tagger.parseToNode(str)
# 形態素分解した文字の数だけ、情報の文字列を「,」で分割して
# 名詞のときだけ表層形を表示しつづける
while nodes:
if nodes.feature.split(‘,’)[0] == ‘名詞’:
print(nodes.surface)
nodes = nodes.next
コードを実行した結果は下記のとおりです。

MeCabが分かち書きで、名詞と判断した単語を順番に取り出すことができましたね!
なお、parseToNodeの「next」は、今持っている形態素の情報の次の形態素にアクセスできるメソッドです。そのため、文章中にあるすべての形態素にアクセスするためには、nextを使って次の形態素を格納する内容(nodes = nodes.next)をwhile文中に記述する必要があります。
以上のように、PythonとMeCabを使えるようになれば、数行で形態素解析ができるようになります。PythonについてはTech Teacherのブログ内で紹介しているので、チェックしてみてくださいね。

データサイエンスを学習するならTech Teacherで!

『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
まとめ
PythonとMeCabを使いこなせるようになれば、簡単に形態素解析ができるようになります。例えば、分かち書きや品詞分解、日本語文章から名詞のみを取り出すことなど、さまざまな形態素解析が数行書くだけで実行できます。
MeCabやPythonのスキルを習得したいなら、「Tech Teacher」がおすすめです!Tech Teacherには難関大学の理系大学生や現役のエンジニアが在籍しており、高度な形態素解析の課題に対しても対応できます。
「MeCabのエラーがわからない」「Pythonの基礎から教えてほしい」などのご相談は、お気軽にお問い合わせください!





