

平均値は一番といってもいいほど基本的な統計量です。その平均値を出す際、
この平均値を出すのは非常に面倒なんじゃないか?
なにか簡単に出す方法はないか?
と思ったことはありませんか?いろいろなパターンごとに平均を出す方法を確認していきます。

本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
数値から平均を出す
平均を出すデータごとにどのような方法があるか確認してみましょう。まずは数値だけの場合です。
計算式を使う
(1+2+3)/3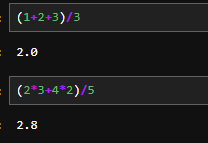
もっとも単純な方法です。Pythonは通常の計算式を打ち込めばそのまま計算してくれます。
リストから平均を出す
list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]このようなリストを用意して、いくつかの方法で平均を出してみます。
計算式を使う
sum(list)/len(list)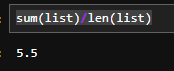
listは標準以下の関数が使用できます。
- sum:( )内のlistの合計値を返します。
- len:( )内のlistのデータの数を返します。
statisticsを使う
import statistics
statistics.mean(list)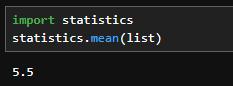
Python標準で使用できる「statistics」ライブラリを使用すると直接平均を計算できます。
- statistics.mean:( )内の平均値を出します。
numpyを使う
import numpy as np
np.mean(list)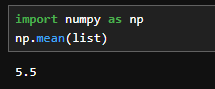
よく使用されるライブラリ「numpy」を使用することでも直接平均を計算できます。
- np.mean:( )内の平均値を出します。
list2 = [[21, 32, 23, 34, 25, 36, 27, 38, 29, 31],
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]]
np.mean(list2)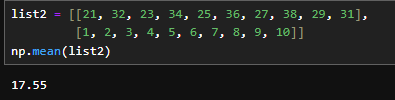
なお、この方法で2次元のデータでも総平均を出すことが可能です。
forやwhieで平均を計算する
forやwhileを使用して計算することも可能です。
#forを使用した場合の例
sum = 0
for i in list:
sum += int(i)
sum/len(list)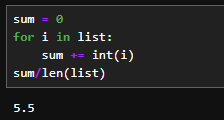
#whileを使用した場合の例
sum = 0
count = 0
while count<len(list):
sum += list[count]
count += 1
sum/len(list)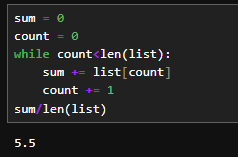
このような方法で平均を出すと、条件に一致した内容のみの平均を出すことも可能です。
sum = 0
count = 0
for i in list:
if i % 2 == 0:
sum += int(i)
count += 1
sum/count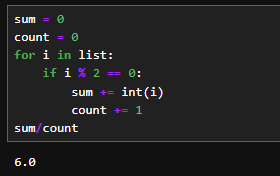
上記の例では偶数のものだけ取り出して平均を出しています。
タプルの平均を出す
tuple = (1, 2, 3, 4, 5, 6, 7, 8, 9, 10)タプルもリストと同じように平均の計算が可能です。前項の「リスト」の部分を「タプル」に置き換えて計算してください。
ディクショナリの平均を出す
dictionary = {
'a':1,
'b':2,
'c':3,
'd':4,
'e':5,
'f':6
}
dictionary.values()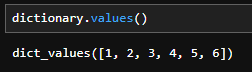
ディクショナリは直接計算できないため、「dictionary.values()」でリスト型に変換します。上記のようにリスト型に変換されたら前項の「リストから平均を出す」の内容に従って計算します。

『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
データフレームの平均値を出す
今回は「scikit-learn」の「iris」データセットを使用して、以下のようなデータを作成しました。
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df_y = pd.DataFrame(iris.target, columns=['target'])
df = pd.concat([df, df_y], axis=1)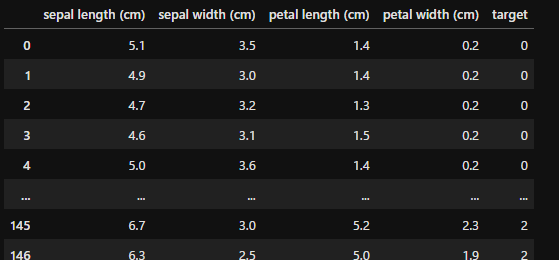
計算式を使う
df.mean()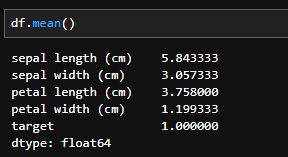
データフレームに「mean」を適用すると各カラムの平均が表示されます。
- df.mean():dfの平均値を出します。dfはデータフレーム名です。
describeを使う
df.describe()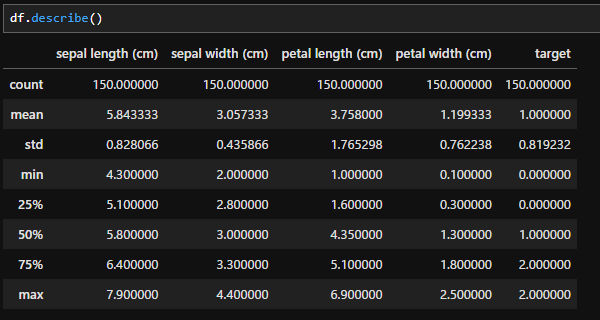
データフレームに「describe」を適用すると、各カラムの統計量が出てきます。この中の「mean」の項目に平均値が出てきます。
- df.describe():dfの統計量を出します。
groupbyを使う
df.groupby('target').mean()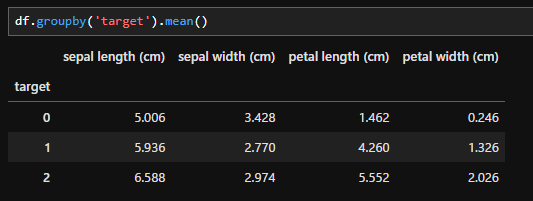
「groupby」を使用して平均を出すことも可能です。groupbyで指定したキーでまとめてそれ以外のカラムの平均値を出します。今回は「target」で取りまとめて、それ以外のカラムの平均値を出します。
df.groupby('target').count()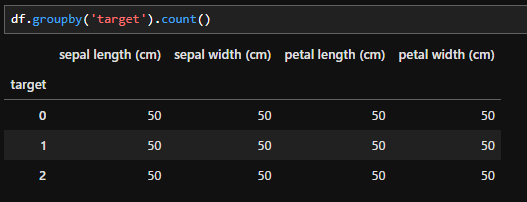
df.groupby('target').sum()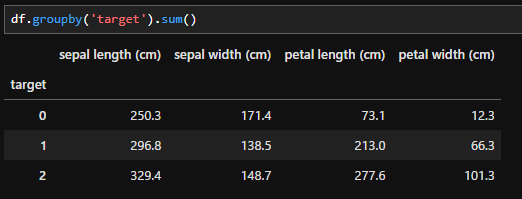
- df.groupby( ).mean():( )内のカラムでまとめて各カラムの平均を出します。
- df.groupby( ).count():( )内のカラムでまとめて各カラムのデータ数を出します。
- df.groupby( ).sum():( )内のカラムでまとめて各カラムの合計を出します。
一括で平均をだす
df = df.drop(['target'], axis=1)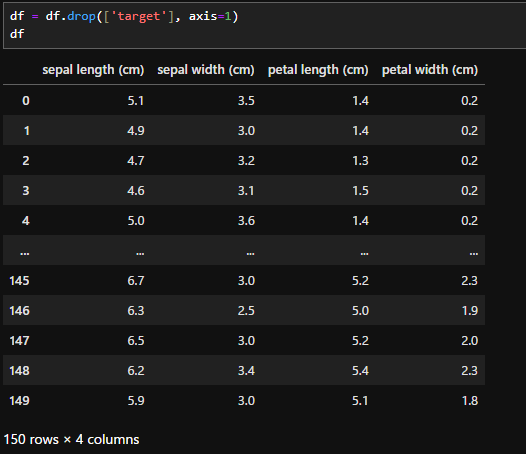
各行のデータについて、それぞれ一括で平均値を出す方法を確認します。「df.mean()」で、「df.mean(axis=1)」と指定すると行ごとの平均値を求めることができます。今回は「target」を計算に入れたくなかったため、「target」のカラムを削除しました。
df.mean(axis=1)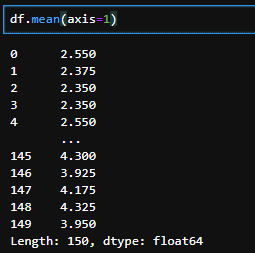
df.mean()にaxis=1を指定することで、各データの平均を出すことが可能です。
df['mean'] = df.mean(axis=1)
df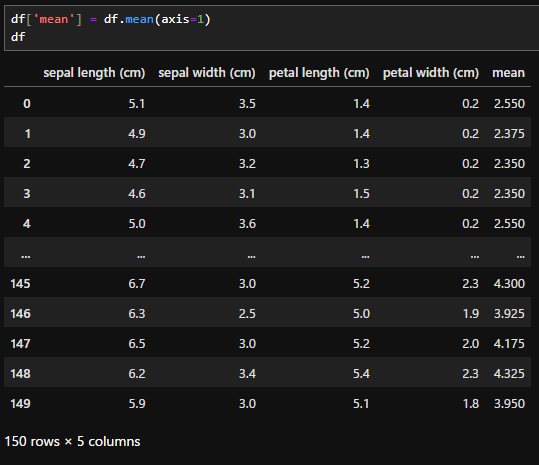
実際に使用する際は、単独で平均値を出すことは少ないと思います。そのまま元データに「平均値」の項目を追加するには、このように追加する項目を指定して計算します。
df['mean'] = df[['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']].mean(axis=1)
df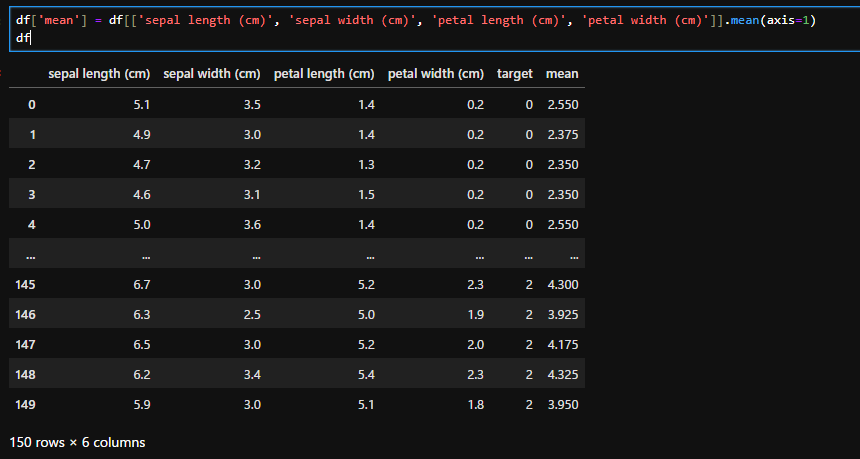
今回の「target」のように平均に含めたくない行がある場合は、上記のように必要なカラムのみ抜き出して計算すれば平均が求められます。データの分析を行う際は、実際にはこのように関係ないデータもたくさん含まれていると思いますので、このようにして計算するとよいと思います。
- df.mean(axis=1):dfの平均値を行ごとに出します。dfはデータフレーム名です。
- df.mean(axis=1):dfの平均値を行ごとに出します。dfはデータフレーム名です。
まとめ
今回はデータのタイプ別に平均の出し方を見てみました。いろいろなデータを扱うなかでいろいろな平均の出し方を知っていると便利なことがあります。すべてを覚えておく必要はないと思いますが、必要な時にこのページで必要な方法を調べて活用していただければと思います。
まとめ
今回はデータのタイプ別に平均の出し方を見てみました。いろいろなデータを扱うなかでいろいろな平均の出し方を知っていると便利なことがあります。すべてを覚えておく必要はないと思いますが、必要な時にこのページで必要な方法を調べて活用していただければと思います。





