

機械学習でモデルを作成する際、データの数が少なかったり、短時間で作成しなければならなかったりしたことはあるでしょうか。そのような場合、転移学習を利用するのが効果的です。
本記事では、機械学習を利用している学生、社会人に向けて、転移学習の概要、メリット、その他の学習方法との違い、実装例を説明します。

本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
転移学習とは?
転移学習とは、事前学習モデルに新たな層を加え、その加えた層の部分だけ学習させる手法です。
例えば、あなたが仕事で、自然言語処理のために深層学習モデルを実装しなければならないとします。しかし、0からデータを収集・加工し、学習させて大規模言語モデル(LLM)を自前で作成するのは膨大な労力がかかります。
そのような場合、GPTやBERTのような、自然言語処理用にすでに公開されている事前学習モデルを利用することで、学習コストを大幅に削減できます。
このように、事前学習モデルをもとにして転移学習をすることで、課題解決のためのモデル作成が簡単になります。
転移学習のメリット3つ
転移学習には以下の3つのメリットがあります。
学習時間を短縮できる
1から深層学習モデルを作成しようとすると、大量のデータを学習させる必要があるため、学習時間や学習コストがかかります。
一方、転移学習では、すでに重みの学習が済んでいるモデルを利用します。そのため、自分で学習させる部分は自分で付け加えた層だけなので、学習時間が短縮できます。
学習データが少なくても精度を上げられる
深層学習は、基本的に学習データが多いほど、精度が上げられます。しかし、自前で大量のデータを収集・加工するのはコストがかかります。
転移学習では、事前学習モデルをもとに学習を進めます。そのため、1からモデルの学習をする必要がないので、学習データが少なくても精度の高い深層学習モデルを作成できます。
汎化性能が高い
各企業、団体が公開している事前学習モデルは汎用性が高く、どのような課題でもある程度の精度が望めます。そのため、事前学習モデルを利用した転移学習では、汎化性能の高いモデルを作成できます。
転移学習のデメリット
モデルの精度が落ちる場合がある
転移学習のデメリットは、事前学習モデルを利用することで、逆にモデルの精度が落ちる場合があることです。
これは、事前学習モデルとこれから学習するデータとの関係性が少ない場合に起こります
転移学習を利用する際は、事前学習モデルが今回の目的とあったモデルであるかを確認してから使用しましょう。
転移学習とファインチューニング・蒸留との違い
転移学習に似たものに、ファインチューニングと蒸留があります。以下では、これらの違いを説明します。
転移学習とファインチューニングの違い
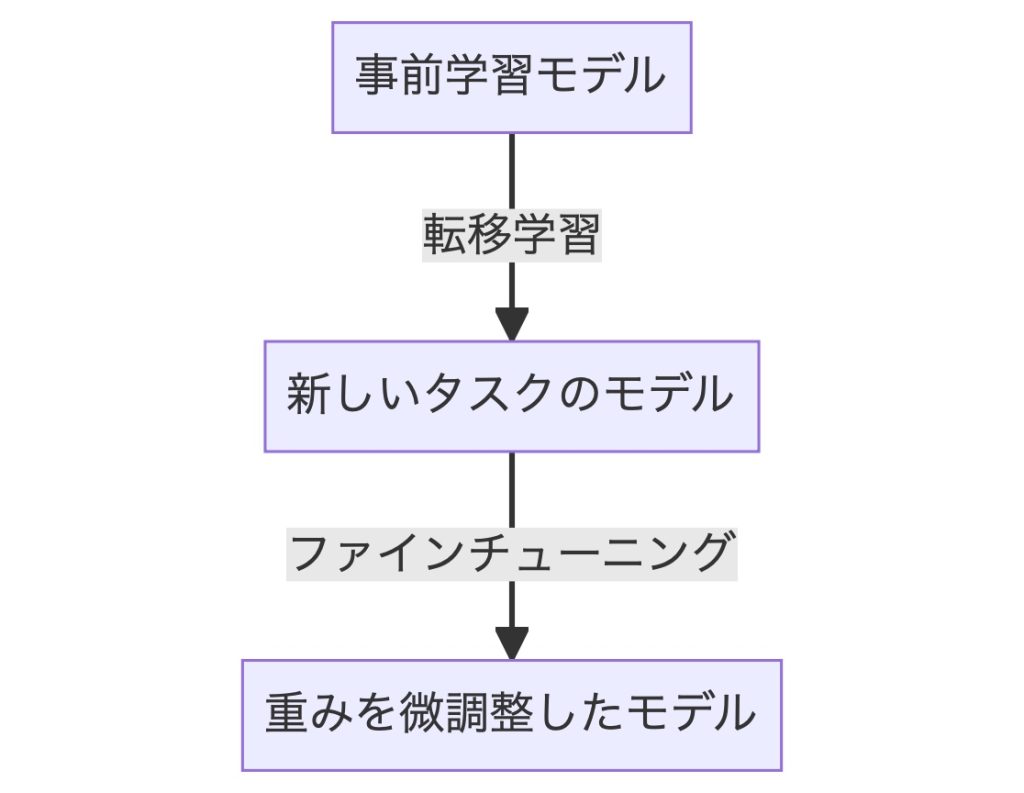
転移学習とは、事前学習モデルに新たな層を加え、加えた層のみ学習させる手法です。
一方、ファインチューニングは、新たに加えた層と事前学習モデル全体に調整を与える手法です。
事前学習モデルは汎化性能が高いため、そのままでも個別の課題にある程度の精度で対応できます。
しかし、さらにファインチューニングをすることで、転移学習より高精度なモデル作成が期待できます。
ただ、転移学習より学習コストがかかるため、その分、計算リソースが追加で必要です。
転移学習と蒸留の違い
蒸留は大規模な事前学習モデルを教師モデルとして、より規模の小さいモデルを作成する手法です。蒸留を行うことで、小さなモデルでも大規模なモデルのような高精度の予測ができるようになります。
一方、転移学習は事前学習モデルに自分で新たな層を付け加える手法なので、モデルの規模は小さくはなりません。
転移学習の使用例
転移学習は以下の3つの分野で主に利用されています。
画像認識
画像認識の分野で転移学習は利用されています。
例えば、画像認識技術を利用すると、猫と犬の写真を区別できます。また、手書き文字を認識して、何が書かれているか読み取らせることも可能です。
画像認識分野での転移学習は以下のような事前学習モデルが利用されます。
- GoogleNet
ISLVRC-2014で優勝したCNNモデルです。 - VGGNet
ISLVRC-2014で2番目に精度が高かったCNNモデルです。構造がシンプルで転移学習に利用しやすいです。 - ResNet
GoogleNetやVGGNetには、ある一定以上の深さになると精度が落ちるという問題がありました。ResNetでは、Skip connectionという層を飛び越える部分を導入したことで、より深い深層学習モデルを作成できるようになりました。
音声認識
音声認識の分野では、事前学習モデルをもとにスマートスピーカーの音声やVtuberの音声などが作成されています。
音声認識分野での転移学習は、以下のような事前学習モデルが利用されます。
- ContextNet
Googleが開発したCNNモデルです。モデルが軽量であるため、転移学習に利用しやすいです。
自然言語処理
自然言語処理の分野では、こちらの質問に答えたり、自動翻訳してくれるAIツールが日々開発されています。
自然言語処理分野での転移学習は、以下のような事前学習モデルが利用されます。
- GPT(Generative Pre-Training)
OpenAIが開発した事前学習モデルです。2022年11月に公開されたChatGPTにも利用されていて、2023年3月14日には、最新モデルのGPT-4が公開されました。 - BERT(Bidirectional Encoder Representation from Transformers)
Googleが開発した事前学習モデルです。Googleの検索エンジンに利用されています。
転移学習の実装例
最後に、転移学習の実装例を見ていきましょう。以下では、与えられた画像が犬か猫かを判別する深層学習モデルを作成します。
まず、今回使用するライブラリをインポートします。
import numpy as np
import tensorflow as tf
from tensorflow import keras次に、データを取得します。
import tensorflow_datasets as tfds
tfds.disable_progress_bar()
train_ds, validation_ds, test_ds = tfds.load(
"cats_vs_dogs",
# データを検証用に10%、テスト用に10%残しておきます。
split=["train[:40%]", "train[40%:50%]", "train[50%:60%]"],
as_supervised=True,
)
print("Number of training samples: %d" % tf.data.experimental.cardinality(train_ds))
print(
"Number of validation samples: %d" % tf.data.experimental.cardinality(validation_ds)
)
print("Number of test samples: %d" % tf.data.experimental.cardinality(test_ds))次に、データを標準化します。
size = (150, 150)
train_ds = train_ds.map(lambda x, y: (tf.image.resize(x, size), y))
validation_ds = validation_ds.map(lambda x, y: (tf.image.resize(x, size), y))
test_ds = test_ds.map(lambda x, y: (tf.image.resize(x, size), y))batch_size = 32
train_ds = train_ds.cache().batch(batch_size).prefetch(buffer_size=10)
validation_ds = validation_ds.cache().batch(batch_size).prefetch(buffer_size=10)
test_ds = test_ds.cache().batch(batch_size).prefetch(buffer_size=10)さらに、データ拡張をします。学習のための画像を平行移動したり、回転させたりすることでデータの量を増やします。
from tensorflow import keras
from tensorflow.keras import layers
data_augmentation = keras.Sequential(
[layers.RandomFlip("horizontal"), layers.RandomRotation(0.1),]
)データの加工が済んだので、モデルを構築します。
base_model = keras.applications.Xception(
weights="imagenet", # ImageNetの事前学習を読み込む
input_shape=(150, 150, 3),
include_top=False,
)
# 事前学習モデルを学習させないようにする
base_model.trainable = False
# 上に新しいモデルを作成する
inputs = keras.Input(shape=(150, 150, 3))
x = data_augmentation(inputs) # データ拡張をする。
# 事前学習モデルの重みのスケールを今回の課題に合わせて調整します。
scale_layer = keras.layers.Rescaling(scale=1 / 127.5, offset=-1)
x = scale_layer(x)
x = base_model(x, training=False)
x = keras.layers.GlobalAveragePooling2D()(x)
x = keras.layers.Dropout(0.2)(x) # Regularize with dropout
outputs = keras.layers.Dense(1)(x)
model = keras.Model(inputs, outputs)
model.summary()最後に、新しく加えた部分を学習させると完了です。
model.compile(
optimizer=keras.optimizers.Adam(),
loss=keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[keras.metrics.BinaryAccuracy()],
)
epochs = 5
model.fit(train_ds, epochs=epochs, validation_data=validation_ds)

学習の結果、正解率(val_binary_accuracy)が97%の深層学習モデルを作成できました。
このように、転移学習を用いると精度の高い深層学習モデルを作成できます。
参考元URL https://www.tensorflow.org/guide/keras/transfer_learning?hl=ja

『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
まとめ
転移学習とは、事前学習モデルに新たに層を追加することで、学習コストを下げながら精度の高いモデルを作成するための手法です。
転移学習は課題と関連のない事前学習モデルを使用すると、精度が落ちることもありますが、適切に利用することで、学習時間が削減できる、少ないデータで学習できる、ある一定の汎化性能が期待できる、といったメリットがあります。
転移学習は学習に膨大なデータと時間が必要な、画像認識、音声認識、自然言語処理の分野で特に利用されており、それぞれの分野で代表的な事前学習モデルが開発されています。
転移学習を積極的に活用して、学習コストを下げながら、深層学習モデルを作成しましょう。
参考文献 一般社団法人日本ディープラーニング協会『深層学習教科書 ディープラーニング G検定(ジェネラリスト)公式テキスト 第2版』翔泳社 2021





