

Q学習とは、強化学習のアルゴリズムの1つです。まず、強化学習について解説し、Q学習やその他の手法についても数式を使わずにわかりやすく解説します。また、Q学習とディープラーニングを組み合わせたDQNの応用例についても紹介します。
- 強化学習の概要
- Q学習
- DQNの応用例

本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
強化学習とは?
強化学習とは、報酬を最大化するような行動を機械に学習させる手法です。犬にお手やお座りを教えることに似ています。犬は、お手やお座りなどの行動をとった際にご褒美(報酬)としてエサがもらえることで、学習します。強化学習は、動物の学習手続きとも似ているとされており、汎用性の高い手法であるため、ゲームやロボットAIの分野を中心に活躍しています。さらに、最近話題となっているOpenAI社のChatGPTにおいても、人にとって好ましい返答をするよう訓練させるために、強化学習の手法が用いられています。
強化学習は、正解ラベルを与えてデータの法則を学ばせる教師あり学習や正解ラベルなしでデータ構造を学ばせる教師なし学習とは異なる機械学習手法になります。具体的には、エージェントと呼ばれる行動主体と環境とのやり取りにおいて、エージェントがもらえる報酬和が最大となるような最適な行動ルールを得る機械学習手法です。ここでいうやり取りとは、エージェントの行動に対して、次の状態への移行や環境からもらえる報酬などが含まれます。最初の例で挙げるならば、犬がエージェントで、お座りやお手が行動、報酬となるエサを渡す人が環境に相当します。
強化学習では、ある状態(State)でエージェントが行動(Action)し、環境から報酬(Reward)が与えられ、新しい状態に移行するという流れを繰り返します。行動の選択を時間単位として、状態を時系列に取り扱います。この流れを箇条書きにすると、以下の①から③になり、これを繰り返すことになります。
①時刻Tにおける状態STのエージェントが行動ATを選択する
②行動によって移行する状態に応じてエージェントに報酬RTが与えられる
③エージェントが次の時刻の状態ST+1に移行する
なお、ここでは、行動選択時の状態の移行を確率的なものではなく、決定的なものとして取り扱っております。また、報酬の時刻をTとおくか、T+1とおくかは教科書によって異なるので注意が必要です。上記の過程を繰り返し、最終的に最大の報酬をもらえるような行動方針を獲得することが強化学習の目標になります。この行動方針のことを方策(Policy)と呼びます。
Q学習とは?
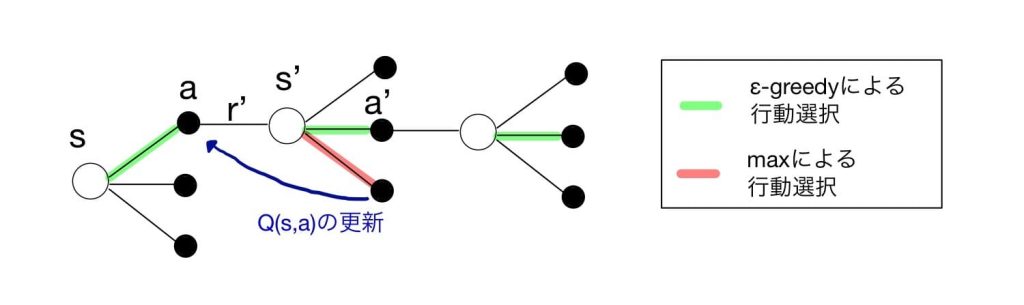 引用:今さら聞けない強化学習(10): SarsaとQ学習の違い
引用:今さら聞けない強化学習(10): SarsaとQ学習の違い
強化学習で最大化したい現在から未来の累積報酬和は、収益と呼ばれます。報酬和に関しては未来の報酬には割引率γ(Discount Rate)が乗算されてγRT+1やγ2RT+2が収益に足し合わされます。通常γは0から1未満の値となり、未来の状態でもらえる報酬ほど、現在の状態の収益への寄与が小さくなります。
ある状態である行動をとった際にその後の収益の期待値を、行動価値関数(Q関数)と定義します。このQ関数を求めることで、方策を評価できます。全ての状態における方策評価ができれば、そこから最適な方策を得ることができるようになります。
方策評価の方法の違いにより、いくつかの強化学習アルゴリズムがあります。Q関数は、現在の状態から将来の報酬和の期待値であるため、これは言い換えれば、最初にもらえる報酬と次の状態でとる行動すべてにおけるQ関数の和に相当します。これにより、価値関数を求める際に最初から最後の状態までもらえる報酬について考える必要がなくなり、前後の状態についてだけ考えればよい問題に変更できます。なお、この関係式は、ベルマン(Bellman)方程式と呼ばれており、強化学習のさまざまなアルゴリズムの基本的な考え方となっています。
Q学習では、適当なQ関数に初期値を設定し、次の状態で得る報酬と最適なQ関数から、今の状態でのQ関数を求めます。エージェントに常に最適な行動をとらせると、全ての状態における価値関数を決定できないため、小さな一定の確率εにおいて、ランダムな行動を選択し、それ以外の確率で最適な行動を選択するε-greedy法がとられます。greedyとは、強欲という意味で、greedy法は、常に最適な行動だけを選択するような方法をいいます。最適な行動を採用することを「活用(Exploration)」、それ以外の行動を試すのを「探索(Exploitation)」と言います。
Q学習以外の方法
SARSA
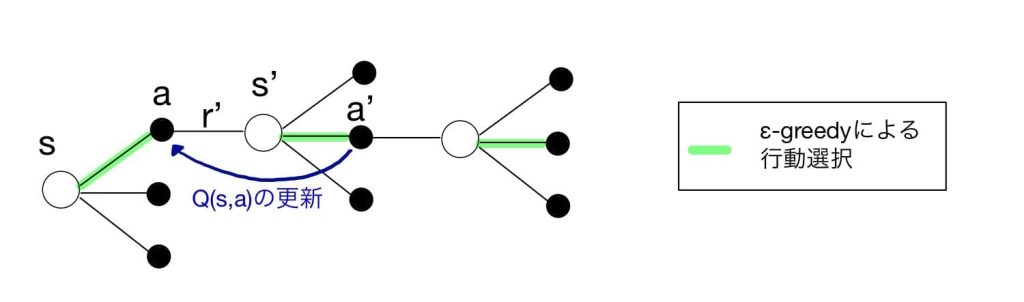 引用:今さら聞けない強化学習(10): SarsaとQ学習の違い
引用:今さら聞けない強化学習(10): SarsaとQ学習の違い
一方、次の状態におけるエージェントが方策に従って行った全ての行動を考慮するのがSARSAと呼ばれる手法になります。
Q学習とSARSAはともに、1つの行動時間差を挟んだ状態から価値関数を求める手法であり、「Temporal Difference(TD)」法に含まれます。SARSAでは、探索と評価に用いる方策は、一般的に同じとするため、方策オン型と呼ばれ、Q学習は、探索にε-greedyを用い、評価には最適な行動を用いているため、方策オフ型と呼ばれます。
TD法(Q学習とSARSA)は、エージェントに行動させ、今の状態と次の状態から価値関数を求める方法になります。
一方、エージェントに行動させ、ある状態から最後の状態まで行動した際の報酬和を実際に計算して直接価値関数を評価する「モンテカルロ法」と呼ばれる手法もあります。何度もエージェントに行動させ、直接求める価値関数の平均を取って更新します。モンテカルロ法は、最後の状態になって初めて更新できるため、最後の状態に達したらリセットさせるようなタスクしか利用できません。一方、TD法は、今の状態と次の状態で価値関数を更新できるため、連続したタスクでも利用できます。
SARSAは、ある状態STにおける行動ATでもらえる報酬RTとその後の状態ST+1と行動AT+1の過程(ST→AT→RT→ST+1→AT+1)から最適なQ関数を求めることからこのような名前となっています。

『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
DQNとは?
 引用:The Unstoppable Power of Deep Learning – AlphaGo vs. Lee Sedol Case Study
引用:The Unstoppable Power of Deep Learning – AlphaGo vs. Lee Sedol Case Study
DQNとは、Deep Q-Networkの略称であり、ディープラーニング(深層学習)とQ学習を組み合わせた深層強化学習手法になります。Q学習では、全ての状態と行動についてQ関数を決める必要があるため、囲碁のような通り数が多い問題において、状態と行動の組み合わせが膨大となり、全てを求めることはできません。そこで、Q関数をディープラーニングによって関数近似する手法であるDQNが用いられています。
ディープラーニングは、近年のAIブームを支える重要な機械学習の手法であり、有名なタスクとして、画像認識や自然言語処理においての教師あり学習や教師なし学習で活躍していますが、強化学習においてもさまざまな応用がなされています。
DQNは、2013年にAtari社のゲームにおいて、人以上のスコアを出したことで有名な手法です。また、囲碁においては、「AlphaGo」が2015年に世界のトップ棋士に勝利したことでも話題となりました。AlphaGoでは、画像認識の手法としてよく用いられるCNN(Convolutional Neural Network)が利用されています。2017年には、モデル同士を対戦させる完全自己対局により学習させた「AlphaGo Zero」や囲碁以外の将棋やチェスにも対応した「Alpha Zero」も開発され、今では人と対戦させるのではなく、AIから実際の手をスコア化して人が学ぶという方法として活用されたりもしています。DQNをベースとした深層強化学習手法はさまざまな改良版が開発されており、ゲーム以外にも、自動運転やロボットに応用されています。




