12章ではDataFrameの行や列を並べ替えるメソッドである『sort_values』『sort_index』について解説します。
練習問題も記事の最後に用意していますので、ぜひ最後まで読んでいってください!
本連載講座【Python ライブラリ編】では、データサイエンスに必要なPythonライブラリやその使い方を基礎から学ぶことができます。
NumPy・Pandas・Matplotlib・Scipy・Seabornについて、初学者の方にも分かりやすいよう丁寧に解説しています。
さらに、学習した内容を定着させられるように各章に演習問題を用意しています。
・Pythonでデータ分析ができるようになりたい
・Pythonの基礎事項は一通り学んだので、さらに深く学びたい
このように考えている方はTech Teacherが運営する【Python ライブラリ編】で、Pythonによるデータサイエンスの学習をすることをお勧めします!
なお、『Pythonについて全く知らない』・『Pythonの基礎事項がまだ分かっていない』という方は、まずコチラの【Python 基礎編】で基礎を一通り学習してからライブラリ編に取り掛かりましょう!
<ライブラリ編 目次>
<ライブラリの基礎>
1章:ライブラリとは
<NumPy>
2章:NumPyの概要と配列(ndarray)
3章:統計量や次元の取得/ソート
4章:配列のインデックス
5章:numpy.whereによる条件制御
6章:配列の結合/分割
7章:乱数
<SciPy>
8章:SciPyの概要と基本操作
<Pandas>
9章:SeriesとDataFrame/統計量の取得
10章:データの読み込み/書き込み
11章:データの取り出し/追加
12章:データのソート
13章:データの結合
14章:階層型インデックス
15章:groupbyによる集計
16章:マッピング処理
17章:欠損値の扱い
<Matplotlib>
18章:Matplotlibの概要
19章:pyplotインターフェース
20章:オブジェクト指向インターフェース
<Seaborn>
21章:Seabornの概要と基本操作

本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
元となるDataFrameの準備
本記事では以下のコードで定義されるDataFrame「df」を使用して解説をしていきます。
まずはコードを実行してデータを準備しましょう。
#DataFrameを作成
data = {
"Employee": ["Charlie", "Bob", "David", "Alice", "Eva", "Grace", "Frank"],
"Location": ["New York", "Los Angeles", "Chicago", "Chicago", "New York", "New York", "Los Angeles"],
"Birth_Year": [1972, 1995, 1987, 1986, 1976, 1986, 1990],
"Annual_Income": [85000, 72000, 63000, 55000, 49000, 68000, 92000],
"Age":[52,29,37,38,48,38,34]
}
df = pd.DataFrame(data)
df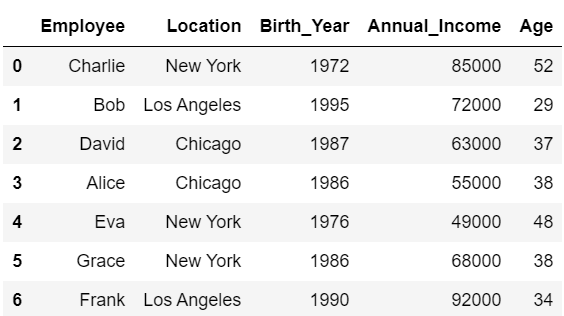
sort_valuesによる並べ替え
『sort_values』メソッドを用いると、DataFrameの行や列を、ある列(行)の値を基準に並べ替えることができます。
本記事ではsort_valuesの基本的な使い方に加えて、特に重要な引数について解説します。
基準の列を指定して並べ替え
『sort_values』メソッドの基本的な使い方は以下の通りです。
df.sort_values(基準となる列の名)
引数として列名を渡すと、指定された列の値を基準にDataFrameの行が並べ替えられます。
以下の例では、先ほど定義した「df」の行を、「Age」列の要素を基準に並べ替えています。
#Ageを基準に行を並べ替え
df.sort_values('Age')
#df:
# Employee Location Birth_Year Annual_Income Age
#0 Charlie New York 1972 85000 52
#1 Bob Los Angeles 1995 72000 29
#2 David Chicago 1987 63000 37
#3 Alice Chicago 1986 55000 38
#4 Eva New York 1976 49000 48
#5 Grace New York 1986 68000 38
#6 Frank Los Angeles 1990 92000 34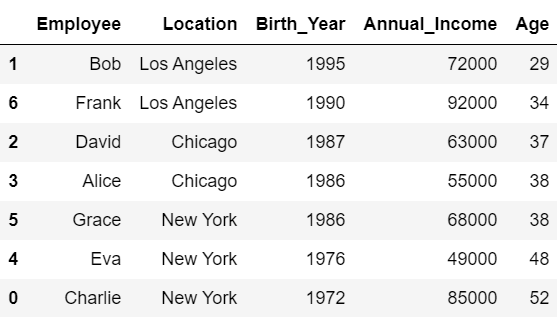
Ageの値が小さい順に行が並べ替えられていることが分かると思います。
また、列名のリストを渡すことで複数の列を基準に並べ替えを行うことができます。
以下の例では、「Location」と「Age」の列を基準にDataFrameを並べ替えています。
#Location, Ageを基準に並べ替え
df.sort_values(['Location', 'Age'])
#df:
# Employee Location Birth_Year Annual_Income Age
#0 Charlie New York 1972 85000 52
#1 Bob Los Angeles 1995 72000 29
#2 David Chicago 1987 63000 37
#3 Alice Chicago 1986 55000 38
#4 Eva New York 1976 49000 48
#5 Grace New York 1986 68000 38
#6 Frank Los Angeles 1990 92000 34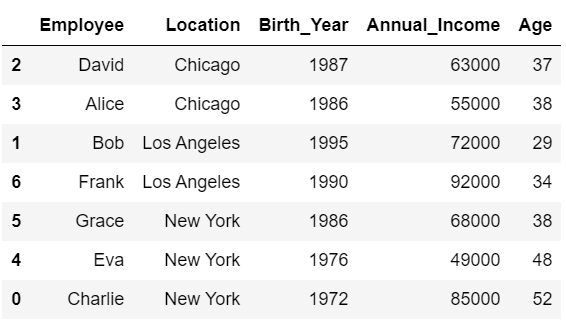
「Location」を基準に並べ替えたうえで、さらに「Age」を基準とした並べ替えが行われています。
引数axis:並べ替えの方向を指定
引数『axis』により、並べ替えの方向を指定することができます。
・axis=0 → 行を並べ替え(ある列を基準にする)
・axis=1 → 列を並べ替え(ある行を基準にする)
デフォルトではaxis=0に設定されています。
以下の例では、axis=1として「df」の行名「2」の行を基準に並べ替えを行っています。
なお、1つの行に数値と文字列が混在していると並べ替えを行うことができません。
そのため、今回の例では数値を要素として持つ列のみを抜き出したdataFrame「df_numbers」を新たに定義しています。
#数値の列のみを取り出す
df_numbers = df[['Birth_Year', 'Annual_Income', 'Age']]
df_numbers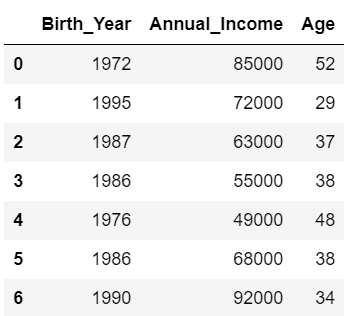
#「2」の行の値を基準に列を並べ替え
df_numbers.sort_values(2, axis=1)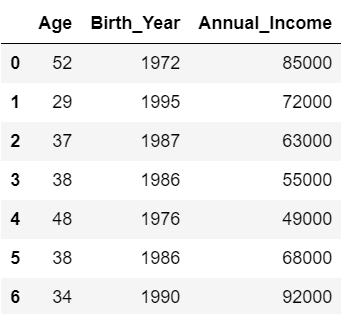
元のデータでは「2」の行は「1987, 63000, 37」となっていましたが、小さい順に「37, 1987, 63000」と並べ替えられました。
これに合わせて、DataFrameの列が「Age, Birth_Year, Annual_Income」の順に並べ替えられています。
引数ascending:降順・昇順の指定
引数『ascending』を用いると、並べ替えの降順・昇順を指定できます。
・ascending=True → 昇順(小さい順)で並べ替え
・ascending=False → 降順(大きい順)で並べ替え
デフォルトではTrueになっているので、昇順に並べ替えられます。
以下の例では、「Annual_Income」列を基準に降順で並べ替えを行っています。
#Annual_Incomeを基準に降順で並べ替え
df.sort_values('Annual_Income', ascending=False)
#df:
# Employee Location Birth_Year Annual_Income Age
#0 Charlie New York 1972 85000 52
#1 Bob Los Angeles 1995 72000 29
#2 David Chicago 1987 63000 37
#3 Alice Chicago 1986 55000 38
#4 Eva New York 1976 49000 48
#5 Grace New York 1986 68000 38
#6 Frank Los Angeles 1990 92000 34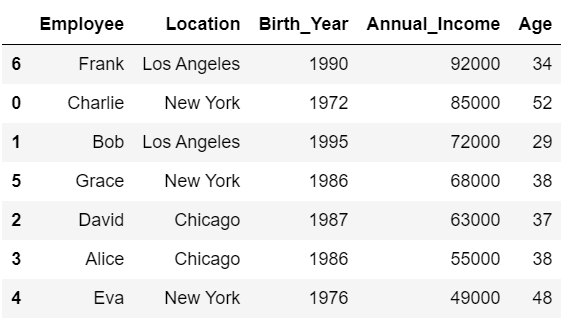
引数key:基準の列に関数で操作を加えてから並べ替え
引数『key』を用いると、基準となる列に関数で操作を加えた後、その列を基準に並べ替えを行うことができます。
「key = 関数名」とすることで、関数を指定します。
このとき、指定する関数は基準となる列(Series)を引数として受け取り、Seriesやリストを返す関数である必要があります。
今回は「Birth_Year」の一の位が小さい順にdfを並べ替えることを考えます。
まずは与えられたSeriesの要素の一の位が格納されたSeriesを返す関数を作成します。
#Seriesの値の1の位だけを取り出す関数
def my_func(s):
return s % 10
#入力に対する出力の例
#入力:[111, 312, 513, 714, 915]
#出力:[1, 2, 3, 4, 5]この関数「my_func」をsort_valuesの引数keyとして指定すると、以下のような結果が得られます。
#my_funcをkeyに設定
df.sort_values('Birth_Year', key=my_func)
#df:
# Employee Location Birth_Year Annual_Income Age
#0 Charlie New York 1972 85000 52
#1 Bob Los Angeles 1995 72000 29
#2 David Chicago 1987 63000 37
#3 Alice Chicago 1986 55000 38
#4 Eva New York 1976 49000 48
#5 Grace New York 1986 68000 38
#6 Frank Los Angeles 1990 92000 34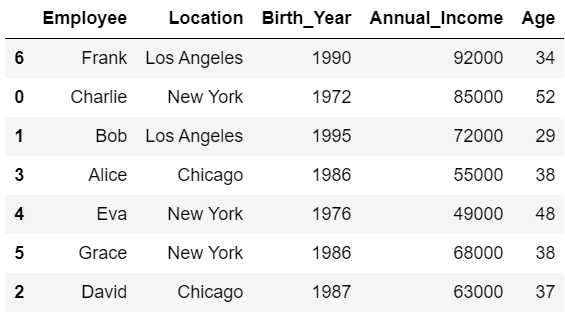
「Birth_Year」の一の位を基準に行が並べ替えられていることが分かると思います。
また、keyで用いる関数として『無名関数(ラムダ式)』を用いることが多いです。
『無名関数(ラムダ式)』は「def」を使用せずに簡潔に定義できる関数のことです。
lambda 引数: 引数に対する処理(戻り値)
と書くと、『:(コロン)』の右側の値が戻り値として返されます。
無名関数を用いて先ほのコードを書き換えると以下のようになります。
#無名関数を使用した場合
df.sort_values('Birth_Year', key=lambda s: s % 10)
#df:
# Employee Location Birth_Year Annual_Income Age
#0 Charlie New York 1972 85000 52
#1 Bob Los Angeles 1995 72000 29
#2 David Chicago 1987 63000 37
#3 Alice Chicago 1986 55000 38
#4 Eva New York 1976 49000 48
#5 Grace New York 1986 68000 38
#6 Frank Los Angeles 1990 92000 34上記の無名関数では、引数である「s」(Series)に対して「s % 10」、すなわち「sの各要素の一の位を格納したseries」が返されます。
実際、my_funcを用いた場合と同じ結果が得られています。
引数ignore_index:インデックスを振りなおす
引数『ignore_index』を用いると、並べ替え後のDataFrameに対して新たにインデックスを振りなおすことができます。
・ignore_index=False → インデックスごと並べ替え
・ignore_index=True → インデックスを振りなおす
デフォルトでは「ignore_index=False」となっています。
以下の例では、「Age」を基準に並べ替えを行う際、「ignore_index=True」としてインデックスを振りなおしています。
#インデックスを0から順に振りなおす
df.sort_values('Age', ignore_index=True)
#df:
# Employee Location Birth_Year Annual_Income Age
#0 Charlie New York 1972 85000 52
#1 Bob Los Angeles 1995 72000 29
#2 David Chicago 1987 63000 37
#3 Alice Chicago 1986 55000 38
#4 Eva New York 1976 49000 48
#5 Grace New York 1986 68000 38
#6 Frank Los Angeles 1990 92000 34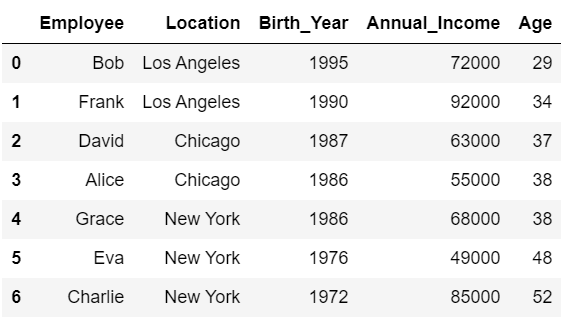
左のインデックスに注目すると、確かにインデックスが振りなおされていることが分かります。
sort_indexによる並べ替え
『sort_index』メソッドを用いると、DataFrameの行名(インデックス)や列名を基準に並べ替えを行うことができます。
行名を基準に並べ替え(axis=0)
『sort_index』メソッドの引数『axis』はデフォルトで0となっており、axis=0のとき行名(インデックス)を基準に並べ替えを行います。
このとき、DataFrameの行が並べ替えられることに注意しましょう。
以下の例では、dfの「Employee」列をインデックスに設定した「df2」を作成し、df2を行名を基準に並べ替えています。
#Employeeをインデックスに設定
df2 = df.set_index('Employee')
df2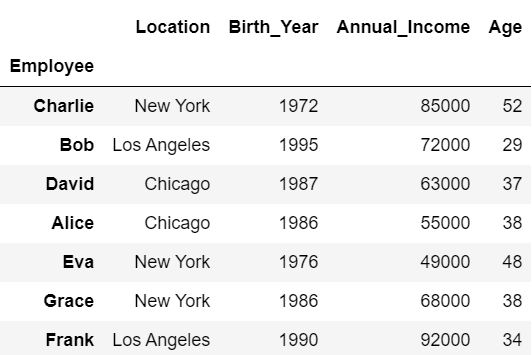
#デフォルトではインデックス(行名)を基準に並べ替え
df2.sort_index()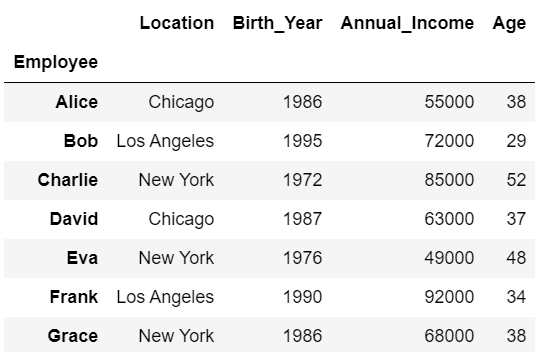
デフォルトではインデックス(Employee)を基準に並べ替えが行われることが確認できました。
列名を基準に並べ替え(axis=1)
引数『axis』を1に設定すると、列名を基準に並べ替えが行われます。
この場合は、DataFrameの列が並べ替えられることに注意しましょう。
#列名を基準に列を並べ替え
df.sort_index(axis=1)
#df:
# Employee Location Birth_Year Annual_Income Age
#0 Charlie New York 1972 85000 52
#1 Bob Los Angeles 1995 72000 29
#2 David Chicago 1987 63000 37
#3 Alice Chicago 1986 55000 38
#4 Eva New York 1976 49000 48
#5 Grace New York 1986 68000 38
#6 Frank Los Angeles 1990 92000 34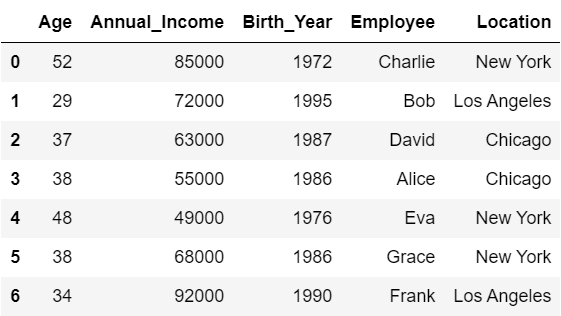
列名が辞書順になるように、dfの各列が並べ替えられていることが分かると思います。
その他の引数(sort_valuesと同じ)
ここまで『sort_index』メソッドの引数axisについて紹介しましたが、その他の引数についてはsort_valuesメソッドと同様です。
以下の例では、引数「ascending」をFalseに設定し、行名の降順でdfの行を並べ替えています。
#降順に並べ替え
df.sort_index(ascending=False)
#df:
# Employee Location Birth_Year Annual_Income Age
#0 Charlie New York 1972 85000 52
#1 Bob Los Angeles 1995 72000 29
#2 David Chicago 1987 63000 37
#3 Alice Chicago 1986 55000 38
#4 Eva New York 1976 49000 48
#5 Grace New York 1986 68000 38
#6 Frank Los Angeles 1990 92000 34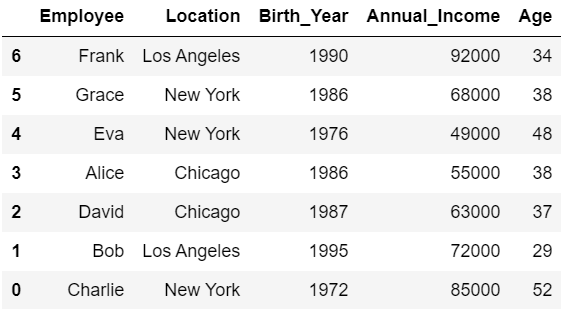

『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
12章の練習問題
以下の練習問題を解いてみましょう。
練習問題
問1. 以下のコードで定義されるDataFrame「df」について、(1)~(2)を出力するプログラムを書いてください。
#DataFrameを作成
data = {
"Employee": ["Charlie", "Bob", "David", "Alice", "Eva", "Grace", "Frank"],
"Location": ["New York", "Los Angeles", "Chicago", "Chicago", "New York", "New York", "Los Angeles"],
"Birth_Year": [1972, 1995, 1987, 1986, 1976, 1986, 1990],
"Annual_Income": [85000, 72000, 63000, 55000, 49000, 68000, 92000],
"Age":[52,29,37,38,48,38,34]
}
df = pd.DataFrame(data)
df
(1) 「Annual_Income」列を基準に行を並べ替えたDataFrame
(2) 「Employee」列の文字列長を基準に、降順で行を並べ替えたDataFrame(ヒント:文字列を要素として持つSeriesの各文字列の長さは「Series名.str.len()」で取得できます。)
問2. 問1で用いたdfに対して、以下の条件を満たすDataFrameを出力するプログラムを書いてください。
dfの列名の長さを基準に、降順で列を並べ替えたDataFrame
解答
(1)
#(1)
df.sort_values('Annual_Income')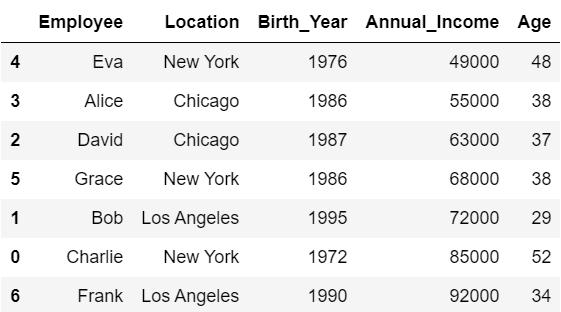
(2)
#(2)
df.sort_values('Employee', ascending=False, key=lambda x: x.str.len())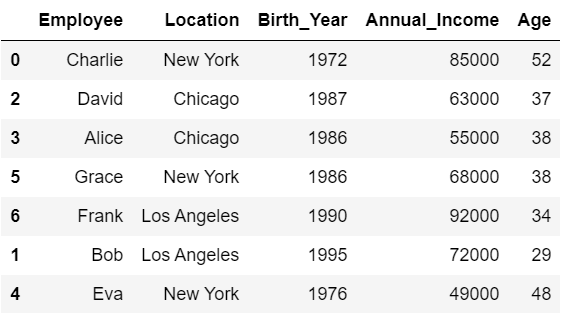
#(2)
df.sort_index(axis=1, ascending=False, key=lambda x: x.str.len())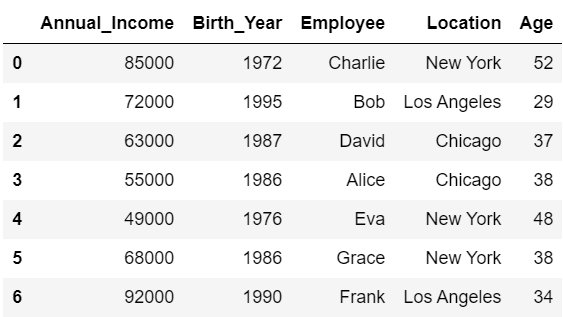
次のページへ