

11章ではPandasにおける『行や列の取り出し』『loc』『iloc』『行や列の追加』『ブールインデックス参照』について解説します。
練習問題も充実していますので、ぜひ最後まで読んでいってください!
本連載講座【Python ライブラリ編】では、データサイエンスに必要なPythonライブラリやその使い方を基礎から学ぶことができます。
NumPy・Pandas・Matplotlib・Scipy・Seabornについて、初学者の方にも分かりやすいよう丁寧に解説しています。
さらに、学習した内容を定着させられるように各章に演習問題を用意しています。
・Pythonでデータ分析ができるようになりたい
・Pythonの基礎事項は一通り学んだので、さらに深く学びたい
このように考えている方はTech Teacherが運営する【Python ライブラリ編】で、Pythonによるデータサイエンスの学習をすることをお勧めします!
なお、『Pythonについて全く知らない』・『Pythonの基礎事項がまだ分かっていない』という方は、まずコチラの【Python 基礎編】で基礎を一通り学習してからライブラリ編に取り掛かりましょう!
<ライブラリ編 目次>
<ライブラリの基礎>
1章:ライブラリとは
<NumPy>
2章:NumPyの概要と配列(ndarray)
3章:統計量や次元の取得/ソート
4章:配列のインデックス
5章:numpy.whereによる条件制御
6章:配列の結合/分割
7章:乱数
<SciPy>
8章:SciPyの概要と基本操作
<Pandas>
9章:SeriesとDataFrame/統計量の取得
10章:データの読み込み/書き込み
11章:データの取り出し/追加
12章:データのソート
13章:データの結合
14章:階層型インデックス
15章:groupbyによる集計
16章:マッピング処理
17章:欠損値の扱い
<Matplotlib>
18章:Matplotlibの概要
19章:pyplotインターフェース
20章:オブジェクト指向インターフェース
<Seaborn>
21章:Seabornの概要と基本操作

本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
行や列の取り出し
まずはDataFrameから任意の列や行を取り出す方法について解説します。
なお、本記事では以下のコードで定義されるDataFrame「df」を用いて列や行の取り出しを解説します。
コードを実行して、dfの中身を確認しておきましょう。
#DataFrameを作成
data = {
"col0": [1, 2, 3, 4, 5],
"col1": [6, 7, 8, 9, 10],
"col2": [11, 12, 13, 14, 15],
"col3": [16, 17, 18, 19, 20],
"col4": [21, 22, 23, 24, 25]
}
df = pd.DataFrame(data, index=["row0", "row1", "row2", "row3", "row4"])
df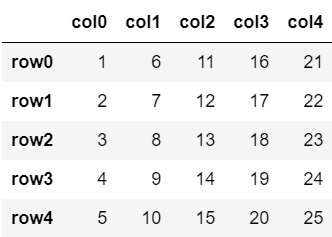
列の取り出し
DataFrameから任意の列を取り出すには、以下のようなコードを書きます。
df[列名]
これにより、列名で指定した列をSeriesとして取り出すことができます。
df['col1']row0 6
row1 7
row2 8
row3 9
row4 10
Name: col1, dtype: int64また、列名のリストをインデックスとして指定すると、リストの順番通りに列を取り出したDataFrameを取り出せます。
#[]の中にリストを入れるので、[]が二重になることに注意
df[['col4','col2']]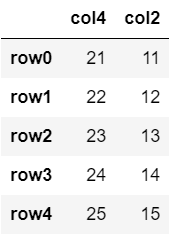
col4、col2の順に指定した列が取り出され、DataFrameとして表示されていることが分かります。
なお、1つの列をリストで指定した場合、SeriesではなくDataFrameとして取り出されます。
行の取り出し(スライス)
df[行名によるスライスor行番号によるスライス]
とすることで、DataFrameから任意の行を取り出すことができます。
『スライス』とはリストなどのデータ構造から一部分を取り出すための記法です。
インデックスの部分で「[start:stop:step]」と指定すると、start番目からstop-1番目までの要素がstep個おきに取り出されます。
なお、インデックスが0から始まることに注意してください。
スライスについて詳しく知りたい方や忘れてしまったという方は、以下の記事で詳しく解説していますのでぜひ参照してください!

行名でスライス
まずは行名を用いたスライスを試してみましょう。
ここで、行名を用いてスライスした場合はstop番目の行も含まれるということに注意しましょう。
df['row1':'row4']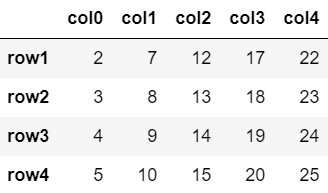
行番号でスライス
行番号でスライスした場合、stop番目の行は含まれません。(リストなどに対する通常のスライスと同じ。)
df[1:4]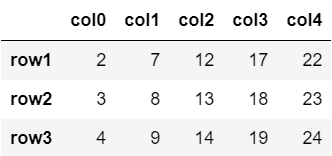
locとilocによるデータの取り出し
『loc』や『iloc』を用いると、スカラー・リスト・スライスによってDataFrameの任意の要素(複数可)を取り出すことができます。
loc
『loc』を用いると、行名や列名を用いてDataFrameの要素を取り出すことができます。
df.loc[行名の指定, 列名の指定]
のように書きます。
「行名の指定」や「列名の指定」の場所には
・行名/列名
・行名/列名のリスト
・行名/列名によるスライス
を書くことができます。
行名/列名で指定
行名/列名で指定すると以下のように1つの要素を取り出すことができます。
#row2の行、col3の列に該当する要素を取り出す
df.loc['row2', 'col3']18行名/列名のリストで指定
行名/列名のリストを用いると、指定した部分をDataFrameとして取り出せます。
#行名/列名のリストで取り出す
df.loc[['row0','row2'], ['col3','col4']]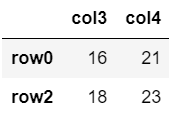
行名/列名によるスライス
行名/列名によるスライスを用いてデータの一部を取り出すこともできます。
このとき、stop番目の行/列も含まれるということに注意しましょう。
#行名/列名のスライスで取り出す
df.loc['row2':'row3', 'col0':'col3']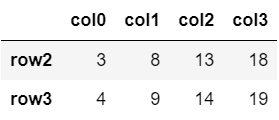
指定方法を複数使用
これまで紹介した3つの方法を用いると、DataFrameの任意の部分を自由に取り出すことができます。
例えば、行の指定を「‘row2’:」、列の指定を「[‘col3′,’col2′,’col1’]」とした、以下のようなデータの取り出しが可能です。
df.loc['row2':, ['col3','col2','col1']]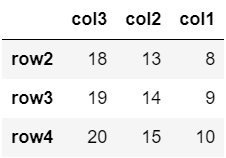
iloc
『iloc』を用いると、行番号や列番号を用いてDataFrameの要素を取り出すことができます。
使い方はlocとほぼ同様で、
df.iloc[行番号の指定, 列番号の指定]
のように書きます。
「行番号の指定」「列番号の指定」の部分には
・行番号/列番号
・行番号/列番号のリスト
・行番号/列番号によるスライス
を書くことができます。
ilocでスライスを用いた場合はstop番目の行/列が含まれないということに注意してください。
以下に、さまざまな指定方法の例を挙げておきます。
行番号/列番号で指定
#2行目、3列目に該当する要素を取り出す
df.iloc[2, 3]18行番号/列番号のリストで指定
行番号/列番号のリストを用いると、指定した部分をDataFrameとして取り出せます。
#行番号/列番号のリストで取り出す
df.iloc[[0,2], [3,4]]行番号/列番号によるスライス
行番号/列番号によるスライスを用いてデータの一部を取り出すこともできます。
このとき、stop番目の行/列は含まれないということに注意しましょう。
#行番号/列番号のスライスで取り出す
df.iloc[2:3, 0:3]
stop番目の行/列を含まないため、locにより行名/列名を用いてスライスした場合とは異なる結果が得られました。
指定方法を複数使用
行の指定を「2:」、列の指定を「[3,2,1]」とした、以下のような指定方法なども可能です。
df.iloc[2:, [3,2,1]]列・行の追加
列の追加
以下のように書くと、DataFrameの末尾に新たな列を追加することができます。
df[新たな列名] = スカラーやリストなど
右辺のスカラーやリストの内容が要素となった、新たな列が追加されます。
こちらのリストに新たに「col5」という名前の列を追加してみましょう。
df['col5'] = 0
df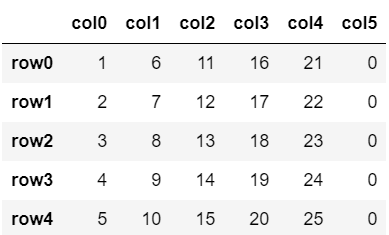
末尾に新しく列が追加されました。
なお、追加する列の要素をスカラーにすると、その値を並べた列が追加されます。
そのため、今回は「col5」としてすべての要素が0である列が追加されています。
また、リストやndarrayで追加する要素を指定することもできます。
df['col6'] = ['a','b','c','d','e']
df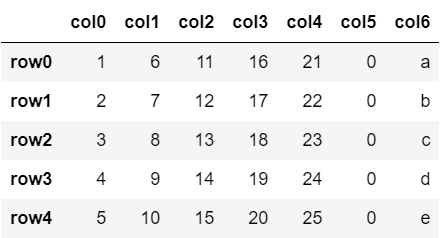
リストの中身を要素としてもつ列を追加することができました。
さらに、既存の列を基にデータを追加(または変更)することもできます。
以下の例では、「col7」を「col0」の要素に100をかけたものとして追加しています。
df['col7'] = df['col0'] * 100
df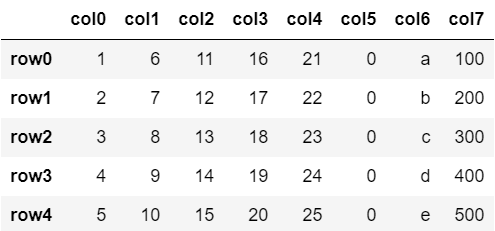
行の追加(locを使う方法)
『loc』を用いてDataFrameの末尾に新たな行を追加することができます。
df.loc[新たな行名] = スカラーやリストなど
locを使用するという点以外は列を追加する場合と同じです。
今回は新たに「row5」という名前の行を追加します。
追加する行の要素は先頭から順に0,1,2…,7とします。
df.loc['row5'] = [0,1,2,3,4,5,6,7]
df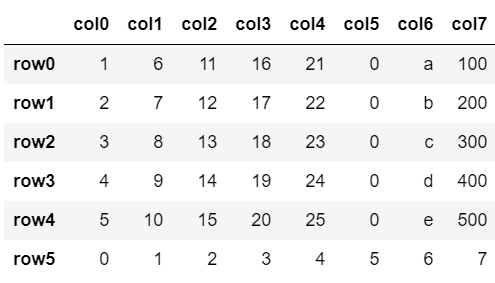
ブールインデックスによるデータの抽出
NumPyの配列(ndarray)と同じように、ブールインデックス参照によって条件を満たすデータを抽出することができます。
df[条件式]
ブールインデックスとは、配列に対する条件式から得られる真偽値配列のことです。
これを用いてDataFrameから特定の条件を満たす行のみを取り出すことができます。
なお、NumPyのブールインデックス参照については以下の記事で詳しく扱っています。
今回は以下のデータを用いて解説します。
コードを実行してデータを準備しましょう。
#DataFrameを作成
data = {
"name": ["Alice", "Bob", "Charlie", "David", "Eva", "Frank", "Grace"],
"city": ["New York", "Los Angeles", "New York", "Chicago", "Houston", "Phoenix", "Philadelphia"],
"age": [25, 30, 30, 35, 35, 45, 50],
"income": [80000, 60000, 65000, 75000, 50000, 70000, 90000]
}
df = pd.DataFrame(data)
df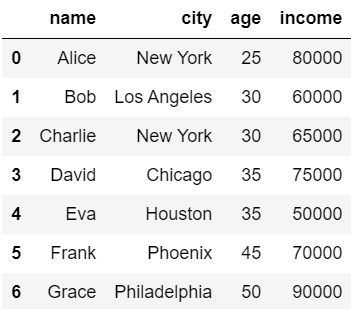
ブールインデックス参照の例として、「age」が30である行を取り出してみます。
df[df['age'] == 30]
このように特定の条件を満たすデータのみを抽出することができるため、非常に便利です。

『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
11章の練習問題
以下の練習問題を解いてみましょう。
練習問題
問1. 以下のDataFrame「df」に対して、(1)~(4)で指定したデータを取り出してそれぞれ出力してください。
data = {
"Employee": ["Alice", "Bob", "Charlie", "David", "Eva", "Frank", "Grace"],
"Location": ["New York", "Los Angeles", "Chicago", "Houston", "Phoenix", "Philadelphia", "San Francisco"],
"Birth_Year": [1995, 1990, 1987, 1982, 1986, 1976, 1972],
"Annual_Income": [85000, 72000, 63000, 55000, 49000, 68000, 92000]
}
df = pd.DataFrame(data)
(1) 「Location」の列
(2) dfの0,1,2行目
(3) dfの1,2行目と1,2列目に該当する部分
(4) 『「Annual_Income」が60000以上』の条件を満たす行
問2. 問1で使用したDataFrameに対して、以下の条件を満たす列を追加してください。
列名:「Age」
内容:2024から「Birth_Year」の要素を引いた値
解答
(1)
#(1)
df['Location']0 New York
1 Los Angeles
2 Chicago
3 Houston
4 Phoenix
5 Philadelphia
6 San Francisco
Name: Location, dtype: object(2)
#(2)
df[0:3]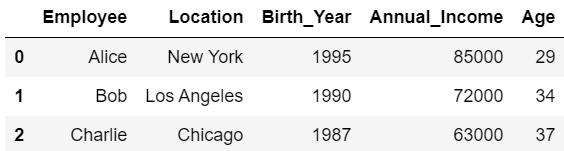
(3)
#(3)
df.iloc[1:3, 1:3]
(4)
#(4)
df[60000 <= df['Annual_Income']]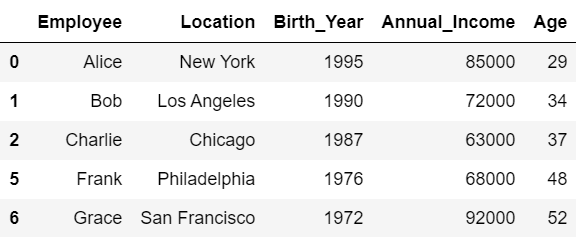
df['Age'] = 2024 - df['Birth_Year']
df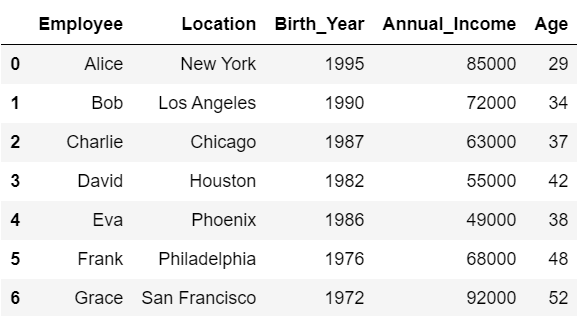
次のページへ






