15章ではPandasの『各統計量を取得するメソッド』、『aggメソッド』および『groupbyメソッド』について解説します。
本記事を読めばPandasにおけるデータの集計の基礎を一通り学ぶことができます。
ぜひ最後まで読んでいってください!
本連載講座【Python ライブラリ編】では、データサイエンスに必要なPythonライブラリやその使い方を基礎から学ぶことができます。
NumPy・Pandas・Matplotlib・Scipy・Seabornについて、初学者の方にも分かりやすいよう丁寧に解説しています。
さらに、学習した内容を定着させられるように各章に演習問題を用意しています。
・Pythonでデータ分析ができるようになりたい
・Pythonの基礎事項は一通り学んだので、さらに深く学びたい
このように考えている方はTech Teacherが運営する【Python ライブラリ編】で、Pythonによるデータサイエンスの学習をすることをお勧めします!
なお、『Pythonについて全く知らない』・『Pythonの基礎事項がまだ分かっていない』という方は、まずコチラの【Python 基礎編】で基礎を一通り学習してからライブラリ編に取り掛かりましょう!
<ライブラリ編 目次>
<ライブラリの基礎>
1章:ライブラリとは
<NumPy>
2章:NumPyの概要と配列(ndarray)
3章:統計量や次元の取得/ソート
4章:配列のインデックス
5章:numpy.whereによる条件制御
6章:配列の結合/分割
7章:乱数
<SciPy>
8章:SciPyの概要と基本操作
<Pandas>
9章:SeriesとDataFrame/統計量の取得
10章:データの読み込み/書き込み
11章:データの取り出し/追加
12章:データのソート
13章:データの結合
14章:階層型インデックス
15章:groupbyによる集計
16章:マッピング処理
17章:欠損値の扱い
<Matplotlib>
18章:Matplotlibの概要
19章:pyplotインターフェース
20章:オブジェクト指向インターフェース
<Seaborn>
21章:Seabornの概要と基本操作

本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
各統計量を求めるメソッド一覧
メソッド一覧
まずはPandasにおいてデータの統計量を求めるメソッドを紹介します。
以下は、各統計量を求めるメソッドのうち特によく使用するものを抜粋した表です。
| メソッド名 | 意味 |
|---|---|
| count | 要素数 |
| mean | 算術平均 |
| std | 標準偏差 |
| min | 最小値 |
| max | 最大値 |
これらのメソッドはDataFrameとSeriesに対して使用することができます。
なお、引数を指定しない場合、すべての列の統計量が計算されます。
統計量の定義については以下の記事で詳しく解説しています。
標準偏差などの定義に不安がある方は、ぜひ参照してください!

使用例
まず以下のデータを準備しましょう。(コピペ推奨)
# 使用するデータ
data = {
'従業員ID': [101, 102, 103, 104, 105, 106, 107, 108, 109, 110,
111, 112, 113, 114, 115, 116, 117, 118, 119, 120],
'名前': ['田中太郎', '山田花子', '鈴木一郎', '佐藤明美', '高橋健太',
'伊藤麻衣', '渡辺隆', '中村さゆり', '小林正義', '木村美穂',
'加藤健太郎', '斎藤あや', '吉田剛', '松本絵美', '田辺浩二',
'岡田真理', '中島大樹', '森田由香', '井上直人', '宮本美和'],
'部署': ['営業', '人事', '開発', '営業', '開発',
'人事', '開発', '営業', '営業', '開発',
'人事', '開発', '開発', '営業', '営業',
'人事', '開発', '人事', '開発', '営業'],
'給与(万円)': [30, 25, 35, 28, 32,
29, 33, 27, 31, 34,
26, 30, 28, 32, 31,
27, 35, 29, 33, 30],
'入社年月日': ['2020-04-10', '2019-08-20', '2021-01-15', '2018-11-05', '2019-12-25',
'2018-10-03', '2020-02-14', '2019-05-22', '2020-08-08', '2018-09-17',
'2019-11-30', '2018-07-12', '2020-03-28', '2019-06-09', '2018-12-15',
'2021-02-03', '2019-04-18', '2020-01-07', '2018-06-25', '2019-10-10'],
'月間売上(万円)': [50, 45, 60, 55, 58,
53, 48, 62, 57, 61,
47, 52, 59, 56, 54,
49, 63, 46, 51, 65],
'残業時間(時間)': [20, 15, 25, 30, 18,
22, 28, 17, 24, 26,
19, 27, 23, 29, 21,
16, 31, 20, 25, 32],
'休暇日数(日)': [5, 8, 6, 4, 7,
3, 6, 5, 7, 4,
8, 5, 6, 4, 7,
3, 6, 5, 8, 4]
}
# データフレームの作成
df = pd.DataFrame(data)定義したデータの先頭部分を『head』メソッドで確かめてみましょう。
#データの先頭部分を表示
df.head()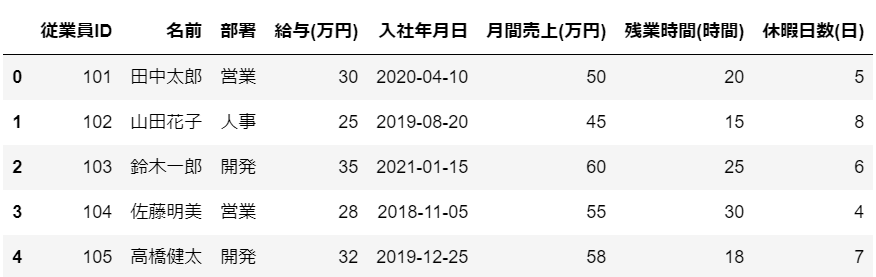
それでは、このデータの「給与(万円)」の平均値を求めてみます。
なお、DataFrameから特定の列/行を取り出す方法については以下の記事で詳しく解説していますので、ぜひ参照してください。

#平均値
x = df['給与(万円)'].mean()
print(x)30.25上の例では、dfから「給与(万円)」列を取り出したSeriesオブジェクトに対してmeanメソッドを適用しています。
また、複数列の統計量を一度に求めることもできます。
#複数列の平均値
df[['給与(万円)', '月間売上(万円)']].mean()給与(万円) 30.25
月間売上(万円) 54.55
dtype: float64他のメソッドも同様にして使用することができます。
ぜひ試してみてください。
aggメソッドで複数の集計を一度に行う
『agg』メソッドを用いることで、複数のメソッドを一度に適用することができます。
df.agg(メソッド名のリスト)
とすることで、指定したメソッドを適用した結果をすべて返します。
以下の例では、dfの給与列にmeanメソッドとstdメソッドを適用した結果をそれぞれ求めています。
#給与の平均値と標準偏差を求める
df['給与(万円)'].agg(['mean', 'std'])mean 30.250000
std 2.917732
Name: 給与(万円), dtype: float64groupby
groupbyメソッドとは
『groupby』メソッドを用いると、特定の列を基準にデータ(行)をグループ分けして集計を行うことができます。
df.groupby(列名).適用したいメソッド
のように書くことで、列名で指定した列を基準にグループ分けが行われた後、メソッドが適用されます。

引用:https://www.yutaka-note.com/entry/pandas_groupby
groupbyメソッドはデータをグループごとに集計したいときなどに非常に便利です。
本記事では先ほど用いたデータ「df」を使用し、groupbyメソッドの使い方を使用例とともに解説します。
基本の使い方
以下の例では、dfを「部署」でグループ化した後、「給与(万円)」列を取り出し、平均値を計算しています。
#部署でグループ化した後、給与列の平均値を求める
df.groupby('部署')['給与(万円)'].mean()部署
人事 27.200000
営業 29.857143
開発 32.500000
Name: 給与(万円), dtype: float64上の例では「df.groupby(‘部署’)」でグループ化されたオブジェクトを作成し、「[‘給与(万円)’]」でそのオブジェクトから給与の列を取り出しています。
その後meanメソッドを適用することで、部署ごとに給与の平均値を求めることができます。
最初は書き方に慣れないかもしれませんが、コードの意味を理解して少しずつ覚えていきましょう。
また、グループ化後のオブジェクトから複数の列を取り出して集計することもできます。
#部署でグループ化した後、月間売上と残業時間の平均値をそれぞれ求める
df.groupby('部署')[['月間売上(万円)', '残業時間(時間)']].mean()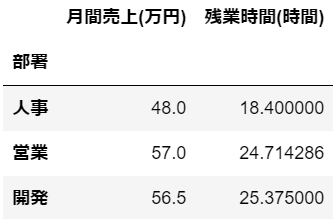
複数列を軸としてグループ化・集計
groupbyメソッドの引数として列名のリストを指定すると、複数列を軸にグループ化・集計することができます。
以下の例では「部署」および「休暇日数(日)」の2軸でグループ化を行った後、それぞれのグループの給与の平均を求めています。
なお、結果が見やすくなるように、「給与」列を要素数1のリストで指定してDataFrameとして出力されるようにしています。
#部署と休暇日数でグループ化した後、給与の平均値を求める
df.groupby(['部署', '休暇日数(日)'])[['給与(万円)']].mean()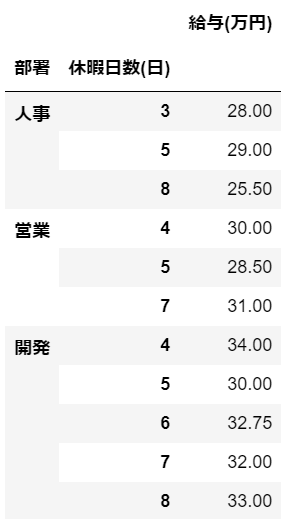
複数列を指定した場合、階層型インデックスを持つデータとして集計結果が返されます。
今回の場合、「部署」と「休暇日数(日)」の2つを階層化されたインデックスとして持つDataFrameが返されています。
なお、階層化インデックスについては以下の記事で詳しく解説しています。
不安な方や初めて聞いたという方はぜひ参照してください。

aggメソッドを用いる
もちろん、グループ化したオブジェクトに『agg』メソッドを用いることで複数の統計量を計算できます。
以下の例では、部署でグループ化後、「月間売上(万円)」と「残業時間(時間)」の2列について、平均値と標準偏差をそれぞれ求めています。
#部署でグループ化した後、月間売上と残業時間の平均値・標準偏差をそれぞれ求める
df.groupby('部署')[['月間売上(万円)', '残業時間(時間)']].agg(['mean', 'std'])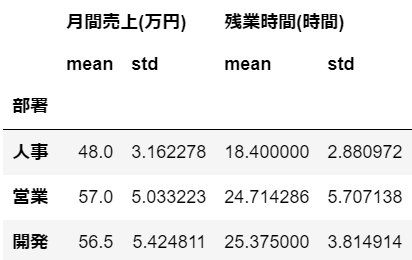
今回使用したデータを用いて、他のメソッドなどを使用するなど、様々な集計を自分自身でで行ってみてください。

『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
15章の練習問題
以下の練習問題を解いてみましょう。
練習問題
問1. 本記事中で用いたdfについて、(1)~(2)を求めてください。
(1) 「休暇日数(日)」列の総和
(2) 「給与(万円)」列と「月間売上(万円)」列それぞれの最小値
問2. 本記事中で用いたdfについて、(1)~(3)を求めてください。
(1) 部署ごとの従業員数
(2) 部署と休暇日数(日)でグループ化した、残業時間の平均値
(3) 部署ごとの月間売上と残業時間の最大値および最小値
解答
(1)
#(1)
df['休暇日数(日)'].sum()111(2)
#(2)
df[['給与(万円)', '月間売上(万円)']].min()給与(万円) 25
月間売上(万円) 45
dtype: int64
(1)
#(1)
df.groupby('部署')['従業員ID'].count()部署
人事 5
営業 7
開発 8
Name: 従業員ID, dtype: int64(2)
#(2)
df.groupby(['部署', '休暇日数(日)'])[['残業時間(時間)']].mean()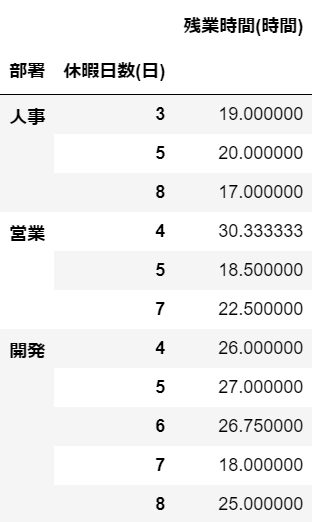
(3)
#(3)
df.groupby('部署')[['月間売上(万円)', '残業時間(時間)']].agg(['max', 'min'])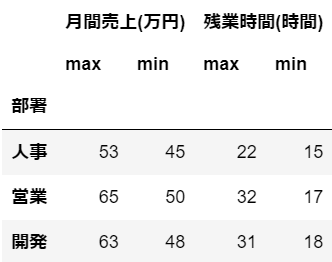
次のページへ