

10章ではPandasのDataFrameを用いた『CSV/Excelファイルへの書き込み』および『CSV/Excelファイルからの読み込み』について解説します。
実際に手を動かしながら学べる内容になっていますので、ぜひ最後までご覧ください!
本連載講座【Python ライブラリ編】では、データサイエンスに必要なPythonライブラリやその使い方を基礎から学ぶことができます。
NumPy・Pandas・Matplotlib・Scipy・Seabornについて、初学者の方にも分かりやすいよう丁寧に解説しています。
さらに、学習した内容を定着させられるように各章に演習問題を用意しています。
・Pythonでデータ分析ができるようになりたい
・Pythonの基礎事項は一通り学んだので、さらに深く学びたい
このように考えている方はTech Teacherが運営する【Python ライブラリ編】で、Pythonによるデータサイエンスの学習をすることをお勧めします!
なお、『Pythonについて全く知らない』・『Pythonの基礎事項がまだ分かっていない』という方は、まずコチラの【Python 基礎編】で基礎を一通り学習してからライブラリ編に取り掛かりましょう!
<ライブラリ編 目次>
<ライブラリの基礎>
1章:ライブラリとは
<NumPy>
2章:NumPyの概要と配列(ndarray)
3章:統計量や次元の取得/ソート
4章:配列のインデックス
5章:numpy.whereによる条件制御
6章:配列の結合/分割
7章:乱数
<SciPy>
8章:SciPyの概要と基本操作
<Pandas>
9章:SeriesとDataFrame/統計量の取得
10章:データの読み込み/書き込み
11章:データの取り出し/追加
12章:データのソート
13章:データの結合
14章:階層型インデックス
15章:groupbyによる集計
16章:マッピング処理
17章:欠損値の扱い
<Matplotlib>
18章:Matplotlibの概要
19章:pyplotインターフェース
20章:オブジェクト指向インターフェース
<Seaborn>
21章:Seabornの概要と基本操作

本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
元になるデータの準備
PandasではCSVやExcelなどのファイルに対する入出力を簡単に行うことができます。
今回はCSVファイルとExcelファイルに対するDataFrameの入出力を解説します。
まずは、元になるDataFrameを準備しましょう。
以下のコードを実行してデータを準備してください。
#データ
data = {
'Name': ['John', 'Alice', 'Bob', 'Emily', 'Michael', 'Samantha', 'David'],
'Age': [28, 32, 45, 29, 35, 40, 38],
'Occupation': ['Engineer', 'Doctor', 'Teacher', 'Artist', 'Lawyer', 'Entrepreneur', 'Architect'],
'Salary': [60000, 80000, 70000, 50000, 90000, 120000, 100000]
}
#DataFrameを作成
df = pd.DataFrame(data)
df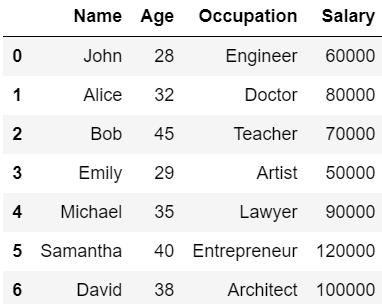
また、カレントディレクトリを確かめるために以下のコマンドを実行してください。
pwdこれを実行することで、現在作業中のフォルダ(カレントディレクトリ)が表示されます。
cdコマンドやmkdirコマンドを使用して、今回作成するファイルを保存したいディレクトリにあらかじめ移動しておきましょう。
Pandasでファイルにデータを書き込む方法
CSVファイルに書き込む
『to_csv』メソッドを用いてDataFrameの内容をcsvファイルに書き込むことができます。
DataFrame.to_csv(‘書き込むファイルのパス’)
とすることで、DataFrameの内容を指定したファイルに書き込むことができます。
以下の例では、先ほど定義したDataFrameの「df」を新しく作成したCSVファイルに書き込んでいます。
なお、ファイル名は「df_to_csv.csv」、保存するディレクトリはカレントディレクトリとします。
df.to_csv('./df_to_csv.csv')CSVファイルが正しく作られているか確認するために、lsコマンドでカレントディレクトリのファイルを見てみましょう。
ls2024/02/14 21:36 <DIR> .
2024/01/24 23:44 <DIR> ..
2024/02/13 16:56 <DIR> .ipynb_checkpoints
2023/10/22 17:50 <DIR> data
2024/02/14 21:36 220 df_to_csv.csv
2024/02/09 20:04 47,390 library_sample.ipynb
2024/02/14 21:34 27,725 pandas_sample.ipynb
2023/10/29 21:53 62,701 sample_notebook.ipynb
2024/02/11 13:00 649,909 test.ipynb上記はlsコマンドの出力の一部ですが、「df_to_csv.csv」という名前のファイルが新たに追加されていることを確認できました。
それでは、作成したCSVファイルをテキストエディタで確認してみましょう。
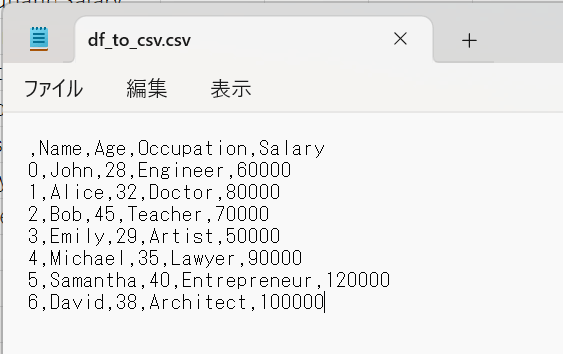
DataFrameの内容がコンマ区切りのCSV形式に変換されていることが分かると思います。
Excelでファイルを開いた場合も、以下のようにDataFrameの内容がしっかり保存されていることが分かります。
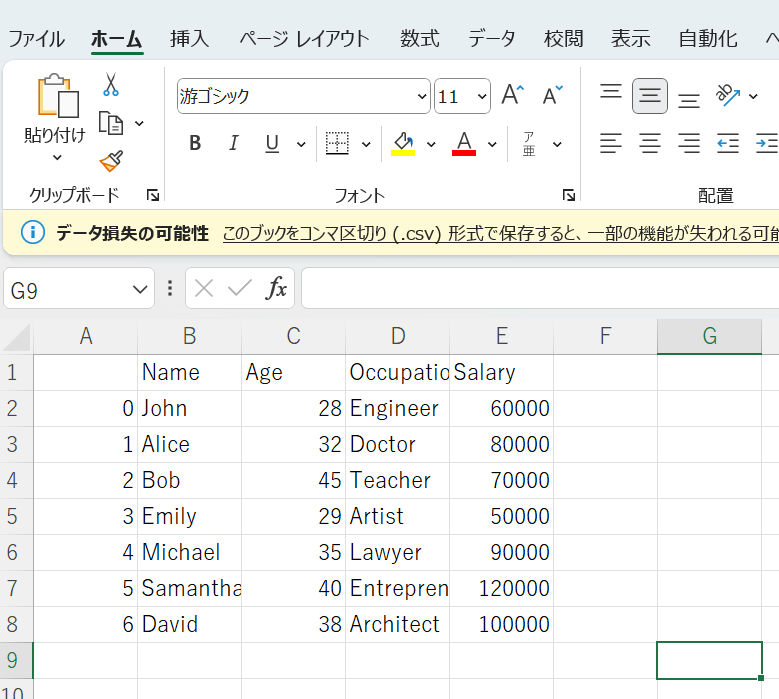
Excelファイルに書き込む
『to_excel』メソッドを用いると、DataFrameの内容をExcelファイルに書き込むことができます。
DataFrame.to_excel(‘書き込むファイルのパス’)
とすることで、DataFrameの内容を指定したファイルに書き込むことができます。
CSVファイルと同じように、「df」の内容をExcelファイルに書き込んでみましょう。
なお、ファイル名は「df_to_excel.xlsx」とします。
df.to_excel('./df_to_excel.xlsx')こちらもlsコマンドでファイルが作成されていることを確認してみましょう。
2024/02/14 21:59 <DIR> .
2024/01/24 23:44 <DIR> ..
2024/02/14 21:40 <DIR> .ipynb_checkpoints
2023/10/22 17:50 <DIR> data
2024/02/14 21:36 220 df_to_csv.csv
2024/02/14 21:59 5,207 df_to_excel.xlsx
2024/02/09 20:04 47,390 library_sample.ipynb
2024/02/14 21:40 28,913 pandas_sample.ipynb
2023/10/29 21:53 62,701 sample_notebook.ipynb
2024/02/11 13:00 649,909 test.ipynbたしかに「df_to_excel.xlsx」という名前のExcelファイルが追加されていますね。
このファイルをExcelで開いてみましょう。
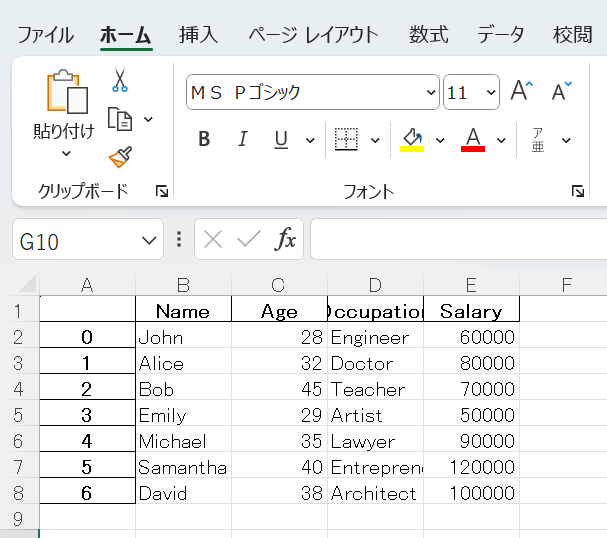
DataFrameの内容が正しく書き込まれていることが確認できました。
Pandasでファイルからデータを読み込む方法
続いてPandasでCSV・Excelファイルからデータを読み込み、DataFrameに格納する方法を説明します。
今回は、先ほど作成した「df_to_csv.csv」と「df_to_excel.xlsx」の2つのファイルをそれぞれDataFrameに読み込みます。
CSVファイルから読み込む
『pd.read_csv()』関数を用いて、CSVファイルの内容をDataFrameにコピーすることができます。
pd.read_csv(‘読み込むファイルのパス’)
このように書くと、パスで指定されたCSVファイルの内容をコピーしたDataFrameが返されます。
それでは先ほど作成した「df_to_csv.csv」を読み込み、DataFrameとして表示してみましょう。
なお、以下のコードは読み込むCSVファイルがカレントディレクトリにあることを仮定しています。
#CSVファイルから読み込み
df_csv = pd.read_csv('./df_to_csv.csv')
df_csv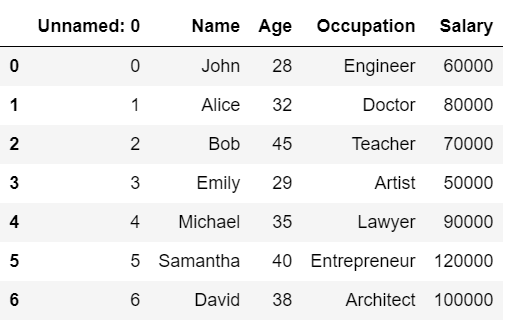
「Unnamed: 0」という不要なカラムが作られてしまっています。
これは、以下の画像から分かる通り、元のCSVファイルの最初の列としてインデックスが書き込まれているためです。
CSVファイルの最初の行をインデックスとしてファイルを読み込むには、引数の『index_col』を0に設定します。
#CSVファイルから読み込み(最初の列をインデックスに指定)
df_csv = pd.read_csv('./df_to_csv.csv', index_col=0)
df_csv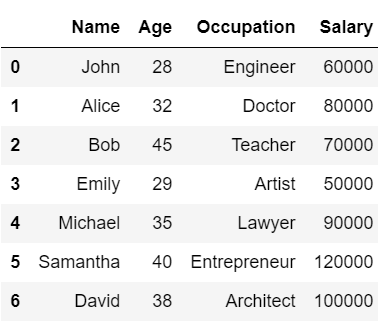
不要なカラムが追加されずに、正しくデータを読み込むことができました。
Excelファイルから読み込む
『pd.read_excel()』関数を用いることで、Excelファイルの内容をDataFrameに読み込むことができます。
pd.read_excel(‘読み込むファイルのパス’)
のように書くことで、パスで指定されたExcelファイルの内容を格納したDataFrameが返されます。
CSVファイルの読み込みと同じように、カレントディレクトリから「df_to_excel.xlsx」という名前のファイルを読み込んでみましょう。
なお、先ほどと同じようにExcelファイルの最初の列をインデックスとして読み込んでいます。
#Excelファイルから読み込み(最初の列をインデックスに指定)
df_excel = pd.read_excel('./df_to_excel.xlsx', index_col=0)
df_excelCSVファイルの読み込みと同じ結果が得られました。

『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
まとめ
いかがだったでしょうか。
本記事では、『DataFrameからCSV/Excelファイルへの書き込み』、『CSV/ExcelファイルからDataFrameへの読み込み』について解説しました。
次回からは、Pandasを用いたデータの加工に関する様々な知識を網羅的に学んでいきます。
一緒にPythonによるデータ分析をマスターしていきましょう!
次のページへ






